

Cache and Materialized View
According to the PostgreSQL wiki,
A materialized view is a table that actually contains rows, but behaves like a view. That is, the data in the table changes when the data in the underlying tables changes.
According to Wikipedia,
... a materialized view is a database object that contains the results of a query. For example, it may be a local copy of data located remotely, or may be a subset of the rows and/or columns of a table or join result, or may be a summary using an aggregate function.
A materialized view is a cache. Since any data can be described with the relational model, we can also say every cache is a partially materialized view – I mean every cache. No matter if it is a cpu cacheline, a DNS entry cached in your browser, or some value in memory your application memoized, it can be reasoned about as a partially materialized view. Even a cached computation result is a partially materialized view; because the CPU must be computing over some data (potentially recursively), and any data can be described with the relational model (maybe suboptimally but that's beside the point). A cache and a partially materialized view are essentially the same thing. In a database (e.g. PostgreSQL, Oracle, etc.), the materialized view is explicitly defined. While in most caching use cases, the partially materialized view is implicit, sometimes hard or impossible (depending on the abstractions in place) to make explicit but exists regardless.
By reasoning about every cache as a partially materialized view (assume it can be explicitly defined), it means if we can cache partially materialized views consistently, we solve the cache invalidation problem. It is not surprising then when Frank from Materialize wrote the following –
Consistency is a watchword at Materialize. We are able to maintain query outputs that at all times correspond exactly to their inputs. This is a solution to the cache invalidation problem, one of the core hard problems in computer science.
We will focus on the OLTP workload for the rest of this post. Imagine we are building a news aggregator website e.g. Hacker News or Lobster. We have normalized schemas – "stories", "users" and "votes". We want to show aggregated vote counts next to each story. For obvious reasons, we do not want to perform the vote aggregation and join on every page load. It is very appealing if we can keep the database schema normalized, and just cache the partially materialized views. We don't want to cache fully materialized views (e.g. Materialize) as that would likely be wasteful for OLTP workloads. Although a partially materialized view can be technically supported in the database itself, there are benefits in supporting it outside of the database – consider when a single page load requires a lot of data from multiple data stores (which is likely the case for a complex website e.g. amazon.com). Externalizing the caching responsibility enables caching data – arbitrary partially materialized views – from multiple backend data stores. memcached is an external key-value cache service. However it requires users to figure out when and which set of cache keys to invalidate when the underlying data changes, which is not a trivial task if the data model is complex.
Noria – Keeping Partially Materialized Views Consistent
The Noria paper from OSDI'18 introduced a new concept called partially-stateful data-flow to solve the consistency problem for partially materialized views. It is built on top of ideas from data-flow systems (e.g. Naiad), stream processing systems, and incremental view maintenance in databases.
Noria intercepts all database queries – it sits in between clients and the database. To use it, a user just needs to define the natural parameterized query (notice the ? mark in the example below) he would use, as if he is querying a normalized database. There is little to none application code change required.

Noria will internally compile the materialized view into a DAG of partially-stateful and stateless operators.
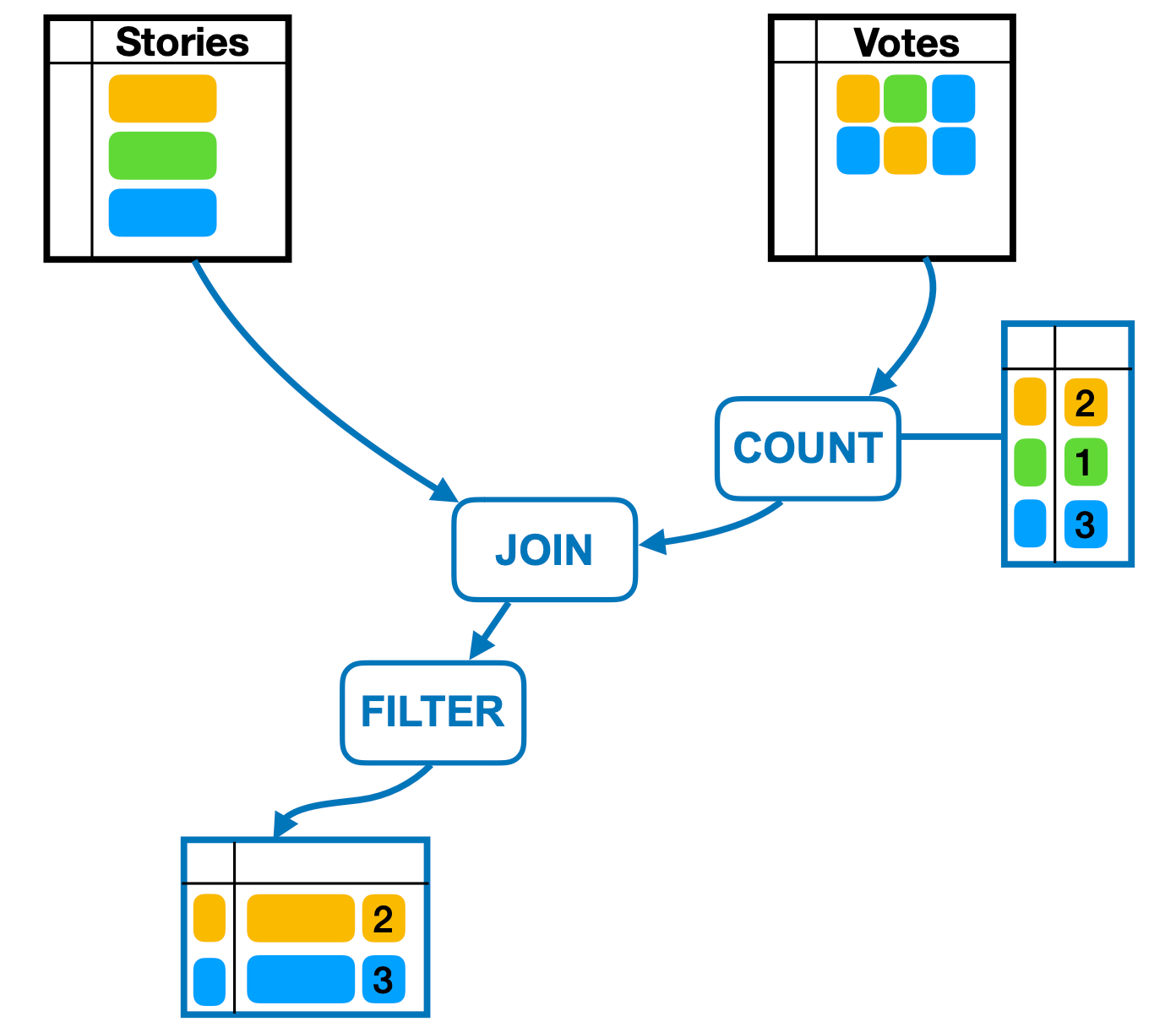
Each stateful operator itself is a cache of its upstream data sources, which can be other operators or the base tables. Aggregation operators (e.g. min, max, count, etc.) are typically stateful to avoid recomputing the entire aggregation due to a single update. Filter, projection and join operators are stateless. All caches (the materialized views, as well as partially stateful operators) get updated on both read path (cache fill) and write path (update). Data can also be evicted to prevent unbounded state growth. And we want to keep the user facing materialized views eventually consistent.
The classic cache race condition happens between a fill and a racing cache invalidation. E.g. a version 5 write invalidates cache, but a racing fill puts version 4 in cache, leading to permanent cache inconsistencies.
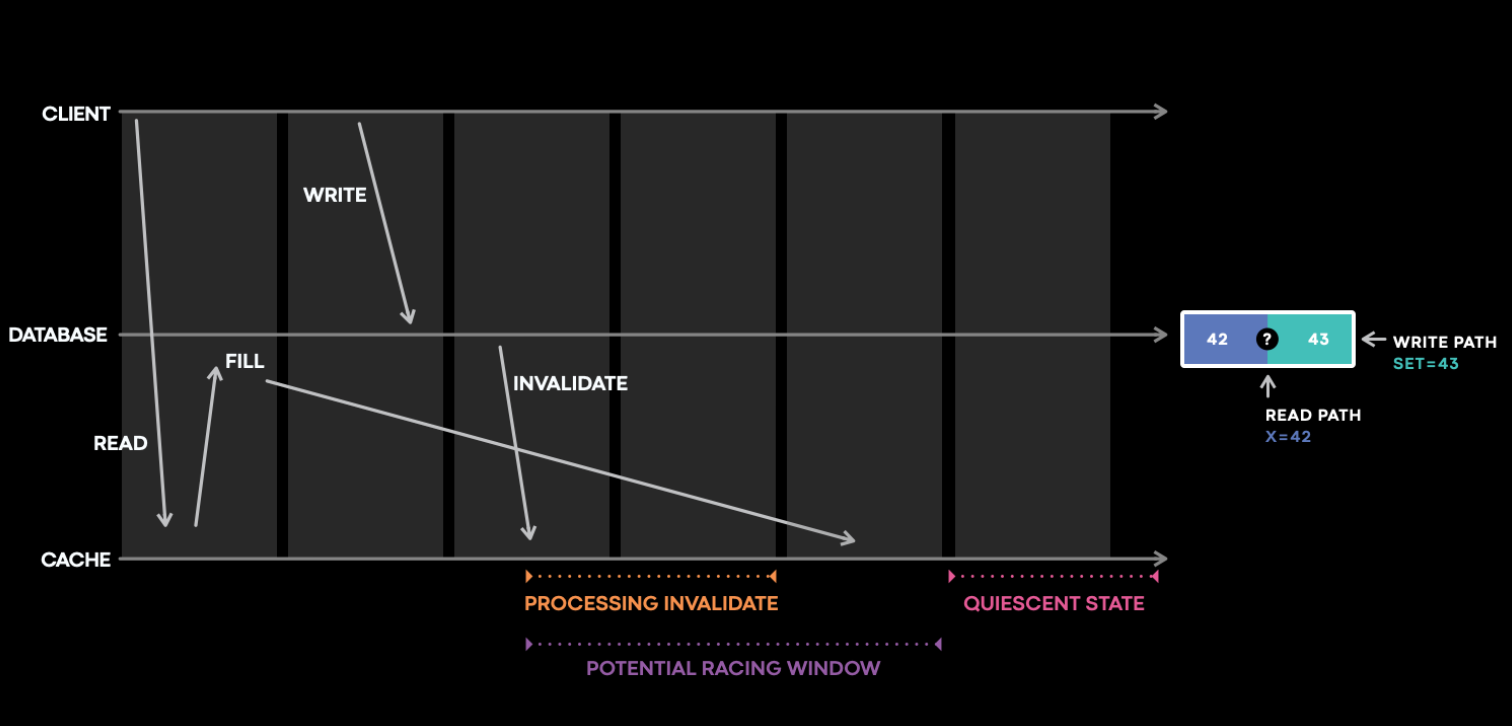
The same applies to Noria; it needs to order cache fills ("upquery" in the paper) and updates to avoid permanent cache inconsistencies in either the stateful operators or the materialized views.
Domain specific caches can leverage versioning primitives to resolve the race (e.g. by putting version in the database and cache). In order to solve the general problem, Noria does not use any versioning primitives. Instead it orders events by forcing some events in the data-flow that can potentially lead to cache inconsistencies to be executed on a single thread.
Upquery responses also commute neither with each other nor with previous updates. (4.3)
... ensuring that no updates are in flight between the upstream stateful operator and the join when a join upquery occurs. To do so, Noria limits the scope of each join upquery to an operator chain processed by a single thread.
Eventual consistency of each individual operator is not enough, as join requires a snapshot from multiple upstream operators. Noria achieves snapshot isolation by executing these join upqueries (fills)
within a single operator chain and exclude concurrent updates.
The snapshot property comes from the exclusion of concurrent updates.
Another unique aspect of Noria, compared to e.g. memcached, is that it explicitly tracks evicted entries (⊥). This way, each stateful Noria operator knows if it has the complete state cached or not (which is impossible for memcached), which is very helpful when it comes to things like range scans, joins, etc. This also means, on cold start, each fully-stateful operator needs to start from a correct state by issuing a large upquery. Partially stateful operators and stateless operators can start just fine without explicit bootstrapping.
Noria manages evictions explicitly – an eviction notice message flows forward along the update data-flow path (from base tables to the materialized views), and mark entries evicted (⊥) along the way. This way, the data-flow can safely discard future update messages (from the base tables) affecting evicted entries. This helps prevent the cache state from unbounded growth and reduces write amplification as well.
Inspirations
Can we borrow some ideas from Noria to improve some of our existing caching products? One big challenge, and a major source of complexity, for memcached users is that they need to figure out the invalidation keys when the underlying data changes. We can use the data-flow to figure out the invalidation keys programmatically.
If the underlying data store supports ordering primitives such as Hybrid Logical Clock, we can probably apply the techniques described in the OSDI'20 FlightTracker paper to provide Causal Consistency in Noria – a big improvement over Eventual Consistency.
If the underlying data store supports HLC and x-shard point-in-time snapshot reads, we can probably build MVCC into stateful operators in Noria and construct cache consistency using HLCs and x-operator/x-shard point-in-time snapshots. This can increase parallelism and throughput.
I won't be surprised if some NewSQL database takes the idea of Noria and speeds up their reads.