

I see folly::IOBuf often used as a return value (sub-)type in RPC definitions for data intensive and high performance applications. I looked at the code, and it says

Well if it's used primarily for networking code, why do applications use it? I don't think people use sk_buff when programming on Linux either right? Abstractions are usually broken in the name of efficiency. In this case, we want to extend the scope of zero-copy networking beyond just the networking stack but also into the application stack.
Zero-copy networking all the way
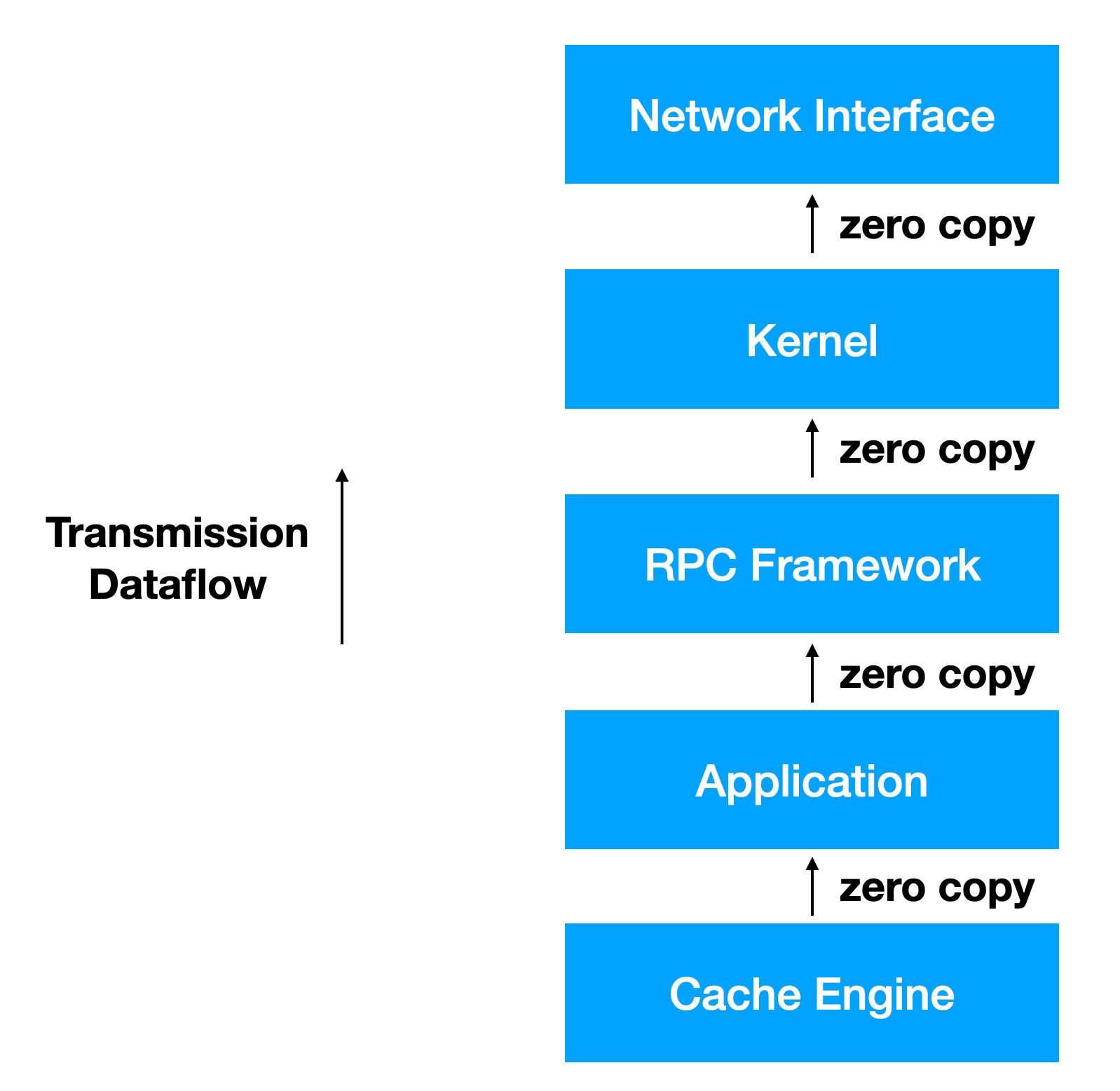
LWN has a great article about zero-copy networking here. The gist is that for data intensive services (usually heavy on data transmission instead of data reception – think about memcached for example), we don't want to copy the data from user space to kernel space. Instead, it would be more efficient if the network interface (hardware) can just read and transmit data directly from the buffer from the user space. Zero-copy in this context is referring to no copy done across the kernel-user space boundary.
Applications usually deal with data with some higher level data structures instead of void* buf directly. Maybe your application has a nice struct representing the reply value type (with a data field, and some additional attributes e.g. trace/debug_string, timestamp, etc. Well there is a cost when you serialize the entire struct and put it in a buffer for transmission (even before kernel locks the buffer and notify the network interface) – strictly worse than even copying the data field. For example, for a high performance cache server, we want to point the buffer to where the data lives in cache, and let the network interface transmit the data directly from a memory location managed by the cache engine. This is to avoid copy across the application-cache boundary.
It is natural then to extend the zero-copy data structure (`folly::IOBuf` in this case) used between the application and system calls, to the interactions in the application with the cache engine as well.
folly::IOBuf
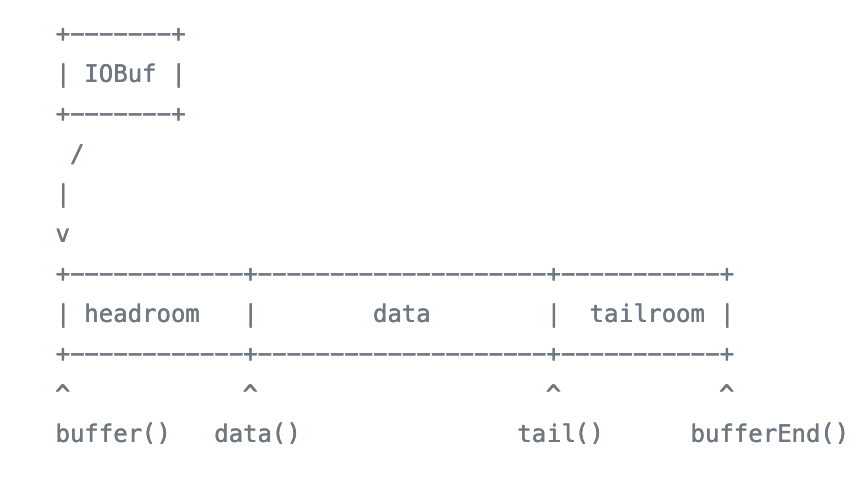
folly::IOBuf's memory layout is very similar to sk_buff's memory layout. It is designed this way so network protocol headers (physical, network, transport) can be added in the headroom without copying the data. The underlying data is refcounted, and it will call a custom deleter when the refcount reaches zero. This is very handy in our cache server example. It allows you to pass the responsibility of memory management from the cache engine (e.g. manage the ref count of the cache item, etc.) to the IOBuf.
It also supports chaining, similar to sk_buff. Chaining is a common feature when it comes to memory management. E.g. cachelib supports chained items as well. Allocating a large contiguous section of memory is hard. Often, for large data, we end up with chained buffers. More over, it comes handy to doing vectored I/O.
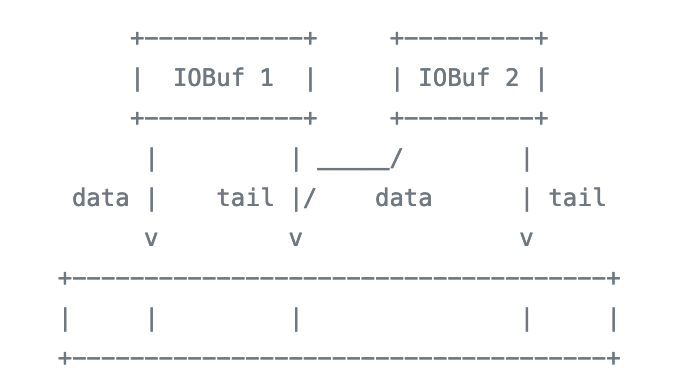
IOBuf supports buffer sharing. It is useful to reduce the number of allocations e.g. when using readv(2). It also provides member functions that convert the IOBuf to iovec to be used with e.g. writev(2).