

FoundationDB is a very impressive database. Its paper won the best industry paper award in SIGMOD'21. In this post, I will explain, in detail, how FDB works and discuss a few very interesting design choices they made. It's a dense paper packed with neat ideas. Many details (sometimes even proof of correctness) are not included in the paper. I added proof wherever necessary.
What is FoundationDB?
It's a non-sharded, strict serializable, fault tolerant, key-value store that supports point writes, reads and range reads. Notice that it provides a key-value API (not SQL). It's also not sharded, meaning the entire key space is essentially on one logical shard. That's it. Once you have a strict serializable key-value store, you can layer a SQL engine and secondary indexes on top. A strict serializable (can be relaxed if needed obviously) key-value store is the foundation (a smaller reusable component), upon which you can build distributed databases almost[1] however you want. This is a great design choice.
Bold Claims
The paper makes a few jaw-dropping claims in the intro.
- FDB is strict serializable and lock-free. How is this possible?
- me: Don't you have to take locks to guarantee order?
- For a global FDB deployment, it can avoid x-region write latency.
- me: Hmm... OK. It's possible if you make some assumptions about failure domains.
- FDB can tolerate f failures with only f+1 replicas.
- me: You gotta be kidding me!
We will come back to all these jaw-dropping claims. If these claims don't excite you, this post and the paper are probably not for you.
Architecture
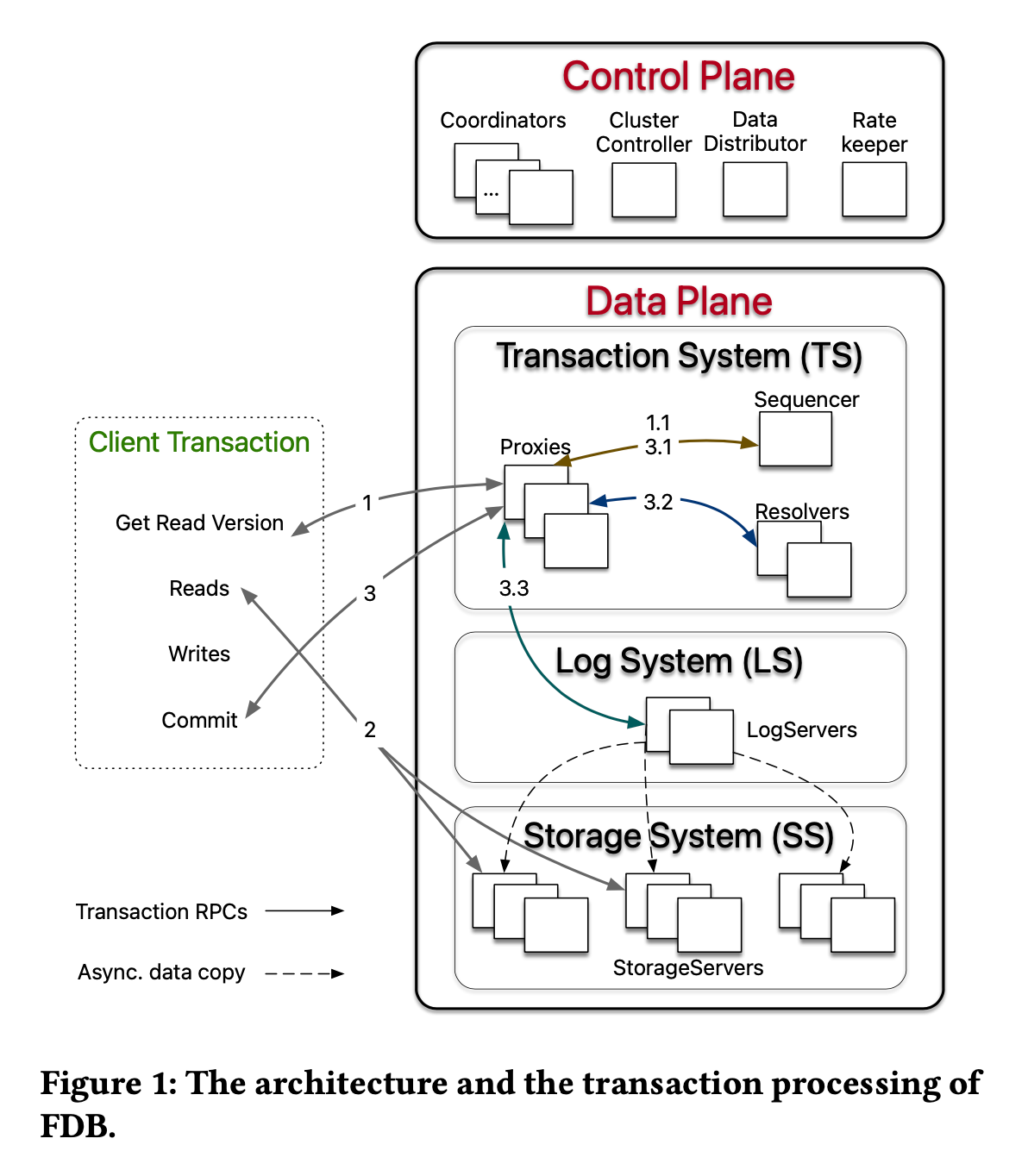
FDB takes the idea of microservice to the extreme (they call it decoupling). Almost every single functionality is handled by a distinct service (stateful or stateless). Embrace yourself for many names for different roles.
Control Plane
The most important Control Plane service in the diagram is the Coordinator. It basically stores small metadata about the entire FDB deployment/configuration (e.g. the current epoch, which gets bumped every time a reconfiguration/recovery takes place). ClusterController monitors the health of all servers (presumably via heartbeats, as it's not mentioned in the paper).
Data Plane
FDB breaks the Data Plane into three parts, Transaction System, Log System and Storage System. Log System and Storage System are mostly what you would expect – a distributed log and a disaggregated, sharded storage. The Transaction System is the most interesting one, among which the Sequencer is the most critical service.
Transaction Management
- A client is always connected to a Proxy, which communicates with FDB internal services.
- The Proxy will get a read-version in the form of HLC (hybrid logical clock) from the Sequencer. Notice that there's only one (not logical) physical Sequencer in the system, which serves as a single point of serialization (ordering). The Sequencer conceptually has the following API, which keeps producing monotonically increasing HLCs(or LSNs).
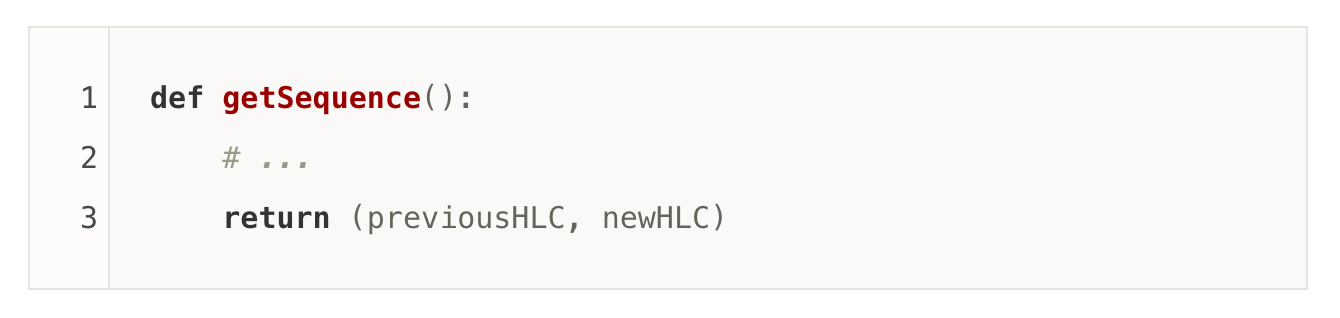 The singularity of the Sequencer is critical, as it provides the ordering of all relevant events of an entire FDB deployment. HLC and LSN are interchangeable for the rest of this post.
The singularity of the Sequencer is critical, as it provides the ordering of all relevant events of an entire FDB deployment. HLC and LSN are interchangeable for the rest of this post. - The client then issues reads to Storage with the specific read-version, acquired from the Sequencer. Storage System will return data at the specific point-in-time indicated by the read-version (an HLC) – MVCC.
- The client then asks Sequencer again for a commit-version.
- Next, it sends the write-set and the read-set to the Resolver. Resolvers are range-sharded and they keep a short history of recent writes. Here, it detects if there are any conflicts (i.e. if the data read earlier in the transaction has changed or not, between
[read-version, commit-version]). - If no conflict is detected, commit the writes to the Log System with commit-version. Once enough ACKs have been received from the logs, the Proxy returns success to the client.
It's basically Optimistic Concurrency Control (OCC), very straightforward. In this example, it actually doesn't even need MVCC. Because if there are conflicts, i.e. what the client read has changed, the transaction will be either aborted or retried anyway. MVCC support in FDB is there to support snapshot reads, and read-only transactions.
Edit: Bhaskar Muppana, one of the authors of the paper, pointed one mistake I had in the following paragraph. It has been corrected. Thanks, Bhaskar.
The reason why Proxy is needed is that it allows reading uncommitted writes within a transaction, which is a very common semantic provided by almost all relational databases. It's achieved by buffering uncommitted writes locally on the Proxy servers, and merging these writes with storage data for reads on the same keys. Client (notice not Proxy) caches uncommitted writes to support read-uncommitted-writes in the same transaction. This type of read-repair is only feasible for a simple k/v data model. Anything slightly more complicated, e.g. a graph data model, would introduce a significant amount of complexity. Caching is done on the client, so read queries can bypass the entire transaction system. Reads can be served either locally from client cache or from storage nodes.
Proxy sits between clients and the transaction system. Its responsibility is to serve as a semi-stateful "client". E.g. it remembers the KCV to aid recovery; it performs batching (of requests from multiple clients) for reducing Sequencer qps.
Resolvers are range-sharded, hence they can perform conflict checks in parallel. That means Proxy needs to wait to hear back from all Resolvers involved in each transaction. How does a Resolver get recently committed keys and their versions? It doesn't actually. Otherwise, it would require a distributed transaction between the Log and the Resolver. The workaround is that Resolvers keep a set of recent write-attempts and their versions. It's possible that a key appears to be recently written in a Resolver while in fact its transaction is rolled back, leading to false positives. FDB claims the false positives are manageable because:
- most workloads fall onto one Resolve (hence it would know if it needs to record the commit-attempt or not)
- the MVCC window is 5 seconds. Waiting it out is not the end of the world, for conflicts are only around a single key – partial unavailability.
How about racing commits? E.g. A Resolver can first admit a transaction with read-version Vr and commit-version Vc. Later, another transaction with commit-version Vr < Vc2 < Vc can hit the Resolver. In this case, the log servers will make sure to accept Vc2 first before accepting Vc, preserving linearizability. All messages in all log servers are sorted in LSN (See 2.4.2, "Similarly, StorageServers pull log data from LogServers in increasing LSNs as well.").
Resolver doesn't need locks to detect conflicts. That's why FDB claims itself to be "lock-free". I found this mention of "lock-free" misleading. In order to realize strict serializability, locks must be used somewhere in the system to implement this total ordering. The Sequencer might have locks inside (not mentioned in the paper). Or even if there's only a single IO thread in the Sequencer, the kernel must use locks to maintain a queue of network packets. Even atomic memory operations are essentially implemented by locks in hardware. Without locks, ordering can't be achieved.
I know you are probably thinking about what if Sequencer or Resolver goes down. We will get there.
Logging Protocol
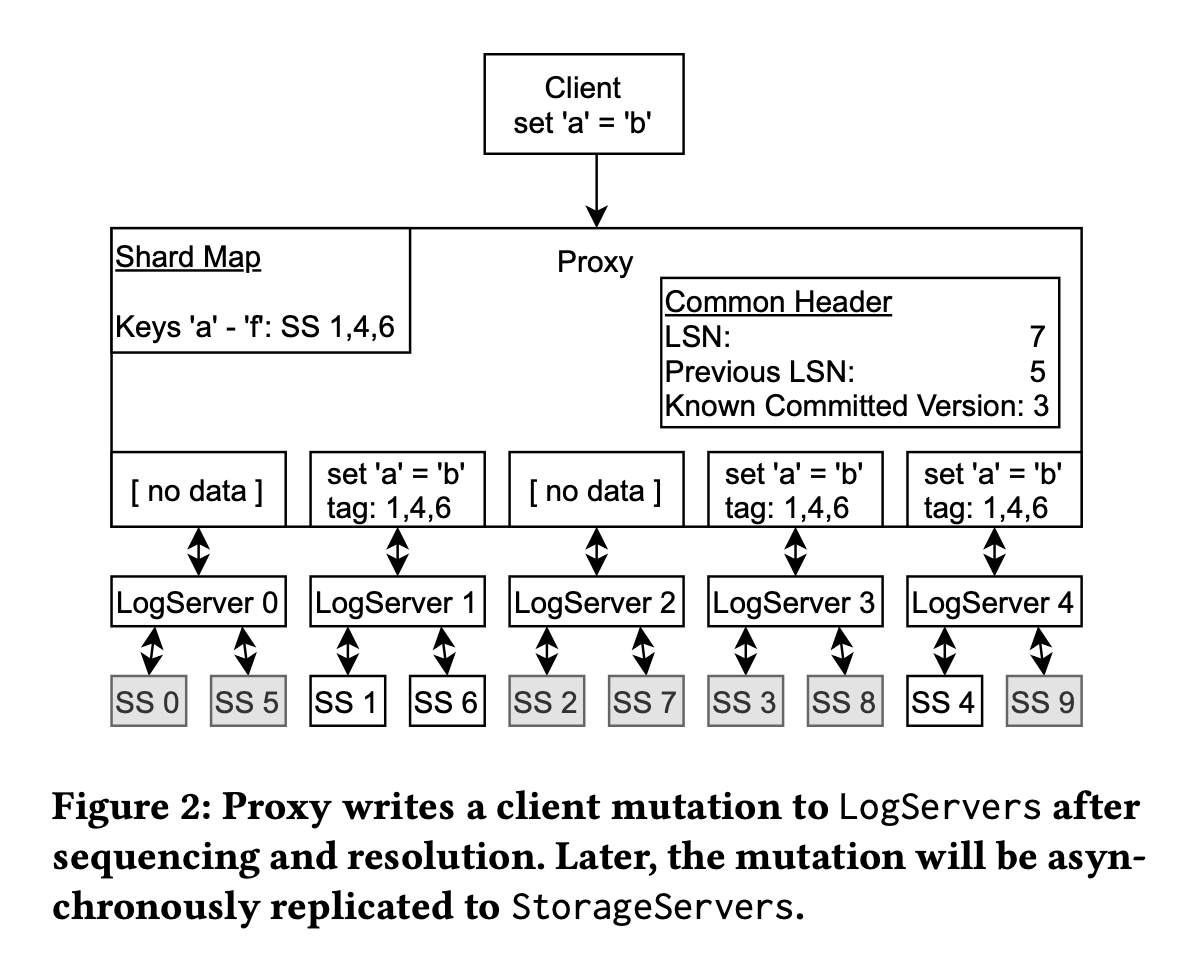
FDB's logging protocol, at first glance, seems pretty straightforward. It has a group of logs, and a separate group of storage servers with distinct replication factors and topologies – another example of physical decoupling in FDB. If you dive a little deeper, you will notice that things are much more interesting.
There are multiple LogServers. Remember, FDB provides an abstraction of one logical shard (non-sharded) database. Commonly, people use logs for sequencing (e.g. Raft), in which case, each log is mapped to a logical shard. So how does FDB provide a single shard abstraction with multiple logs? The answer is FDB decouples sequencing from logging. There is only one Sequencer in the system, which maps to the single shard abstraction (ordering). It enables FDB to have multiple logs, as they do not perform the job of ordering, which logs in other systems usually do. This design is just brilliant. Whoever performs the job of sequencing must be singular. You will get higher throughput and lower latency by having a dedicated role just doing sequencing, and nothing else. In contrast, systems like Raft couple sequencing and logging, which inherently pay a performance cost. In FDB, the Sequencer is physically a singleton – there's a single process. We will talk about failure recovery very soon. Here's what the logging protocol looks like,
- Proxy broadcasts a message to all LogServers. Each message will have a common header including
LSN,prevLSNandKCV.KCVis the last known committed version from the Proxy. It should always be less than theLSN(KCV < LSN), as the transaction associated withLSNis still in progress (hence not committed).KCVcaptures an incomplete local view of the world, which will be used later for the recovery process. - Not all broadcast messages include data. E.g. key
Ais stored on storage shardS. Coordinator maintains an affinity map (each storage server has one preferred LogServer). In this case, data will only be included in the message sent to shardS's preferred LogServer (and potentially additional LogServers to satisfy replication requirements). All other messages to other LogServers will only include the common header. - Once the data is in the log, it will apply to the storage node. It's not super interesting, although there are some performance improvements mentioned in the paper.
There are a few interesting details above. Proxy broadcasts a message to "all" logs. Why all logs instead of only the replicas for the key? Because all messages are applied in order on each log. There can be no gaps. Also, as you will see later, that it's critical for the recovery process. Another related question is why sending messages without data to other logs? This is a performance optimization, as only logs associated with the underlying storage nodes need to have data stored.
Because FDB decouples sequencing from logging, now committing to the logs becomes a distributed transaction problem – e.g. what if log-1 has some data stored, while log-2 doesn't, for an aborted transaction. Does FDB need to perform 2pc? No, actually.
FDB here basically adopts the Calvin approach. It's the same idea that Prof. Abadi posted. The keyword is deterministic. We don't need 2pc here, because Proxy writing to multiple logs is performed blindly (a.k.a unconditionally). Sure, errors can happen. If they are transient e.g. timeout, Proxy can always try again – it will never be blocked by another log commit. This is, by the way, why FDB can afford letting Proxies broadcast each message to all logs.
In this case, the only failure scenario that can actually block log commit and require rollback, is when LogServers actually fail (e.g. crash). We will talk about the recovery process soon.
Notice that in the diagram above, there are 5 logs and 10 storage nodes (and one Sequencer not in the diagram). #StorageNode > #Logs > #Sequencer is not a coincidence. A single Sequencer can support multiple logs, as a Sequencer is much more lightweight (not having to write to disk). A single log again can support multiple storage nodes, as logs are relatively cheaper than storage (you can prune logs, sequential writes are cheaper, etc.).
Recovery Process
Finally, the real fun begins. What happens if the Sequencer fails? Resolvers fail? LogServers fail?
- Failures are detected by the ClusterController (via heartbeats according to the source), who explicitly triggers the recovery process.
- The Sequencer locks and reads the previous states from Coordinators. It can be a new Sequencer instance, running the recovery process, if the previous Sequencer is in a faulty state. That's why we need to lock the Coordinator here, to avoid multiple Sequencers making topology changes at the same time. The paper doesn't talk about what happens if the recovery Sequencer itself crashes, leaving the Coordinators locked forever. This is a classic consensus problem. Given the Coordinators are already running Paxos, this is not a hard problem to solve. E.g. You can think of each recovery itself being a Paxos Proposal. If a recovery Sequencer died halfway, another Sequencer can always come and discover the previous chosen value if any, or propose a new epoch – starting a new recovery process.
- Previous states include information about all old LogServers. The Sequencer then stops old logs from accepting new transactions. The Sequencer knowing it's running a recovery process, obviously won't accept new transactions. But if there's another old Sequencer instance running, it can still accept new transactions. Hence we need to stop the old logs to avoid potential dataloss. Another reason for contacting the old LogServers is to discover the end of the redo log (the last committed LSN).
- The Sequencer recruits a new set of Proxies, Resolvers, and LogServers.
- Write the new system states to the Coordinators, and release the lock.
- Finally, the new Sequencer starts accepting new transactions.
Unlike other fault tolerance algorithms, e.g. Paxos, FDB's recovery process has downtime – from the shutdown of old LogServers to when the new Sequencer starts accepting new transactions. One can argue that this is not really fault tolerant. I personally think it's totally fine to have partial downtime to heal a system (given a short one, which is the case for FDB), e.g. unavailability for a single shard. It's not like systems such as Paxos or Raft have 100% availability even when the simple majority of hosts are always up and running. However FDB has only one logical shard. Its recovery process causes downtime for the entire deployment and the entire key space.
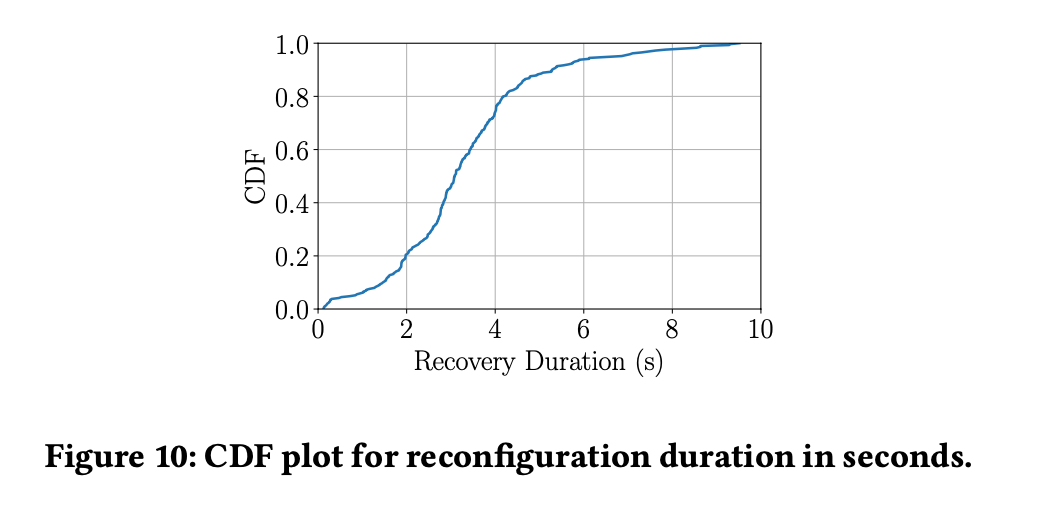
P50 downtime for FDB's recovery process is 3.08s. That means no one can write to FDB at all during this window. The paper argues clients can still read from storage nodes unaffected.
During the recovery, read-write transactions were temporarily blocked and were retried after timeout. However, client reads were not impacted, because they are served by StorageServers.
This statement seems not completely accurate. Snapshot reads are unaffected. But if Sequencer is down, no read-only transactions can be processed either. FDB is read-heavy. It's very reasonable to assume that most of the production read workloads are snapshot reads (instead of read-only transactions). Claiming minimum client visible impact is reasonable.
If a system allows downtime, it can tolerate a lot of replicas going down without affecting it's availability. E.g. With the simplest leader-follower setup, a single leader can have any number of followers (let's say 10). In this case, with a total replication factor of 11, in theory, we can tolerate up to 10 failures without a single second of downtime.
Proxies are easy to recover, as they are mostly stateless (just keeping track of a KCV locally). Resolvers are stateful, but it's safe to discard all Resolvers data from the previous epoch. Because it's impossible to have conflicts spanning across two epochs, as you can't have read-write transactions that span two epochs (as a completely new set of Proxies are recruited). That leaves us with the logs and the Sequencer, which are harder to recover. We just need to know the last committed LSN from the old logs to start a new Sequencer instance. Let's take a closer look at the recovery process of the LogServers.
Log Recovery
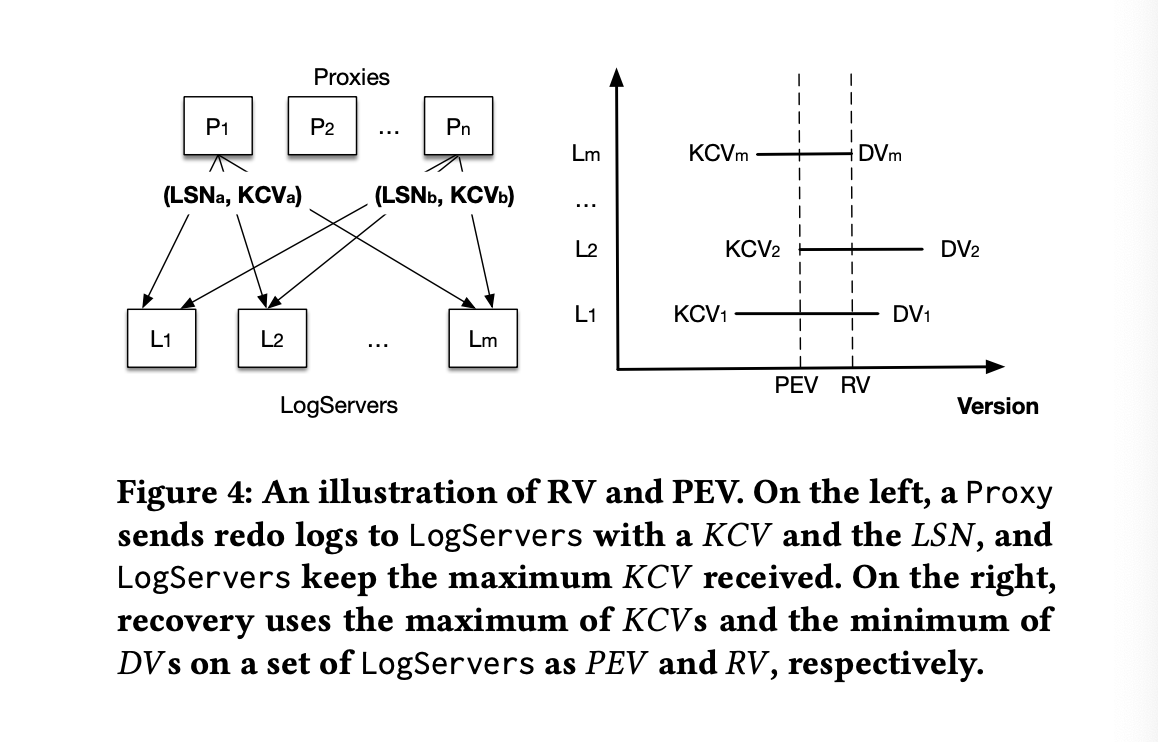
For a LogServer deployment with m hosts and replication factor k, here's how the algorithm looks like:
- Each log maintains
DV(Durable Version, the maximum persisted LSN) andKCV(Known last committed version, the latest committed version known from the Proxy). Both DV and KCV are piggy-backed on each message from Proxy to the logs. - The Sequencer attempts to stop all old logs.
- After hearing back from m-k+1 logs, the Sequencer knows the previous epoch has committed transactions at least up to
max(KCVs). We callmax(KCVs)herePEV(Previous Epoch's end Version). The new Sequencer will start its epoch fromPEV+1.
It seems pretty straightforward. However, the paper mentions another variable RV (Recovery Version) to be min(DVs), and it talks about copying data between [PEV+1, RV] from the old logs to new logs and discarding logs after RV. This is for,
- providing failure atomicity when log commit fails partially (in which case, we need to perform rollback)
- preserving (healing replication factor) for data that are committed at LSN > PEV
Proof of Correctness
The paper didn't include any proof for the correctness of the recovery process. I will explain and prove its correctness here.
Notice that any log message arrived at the logs have already passed the conflict detection, hence safe to be durably stored. Especially given the fact that data stored might have already been read by another client, we can and should err on the side of preserving more of the old logs except when it's not safe to do so. We know for sure that all transactions before PEV are committed. We just need to find the tail of the redo log, where
- partial failures might be happening, for which we must rollback, and
- no clients have ever seen the data yet (because it's the tail)
Let's take a closer look at this diagram.
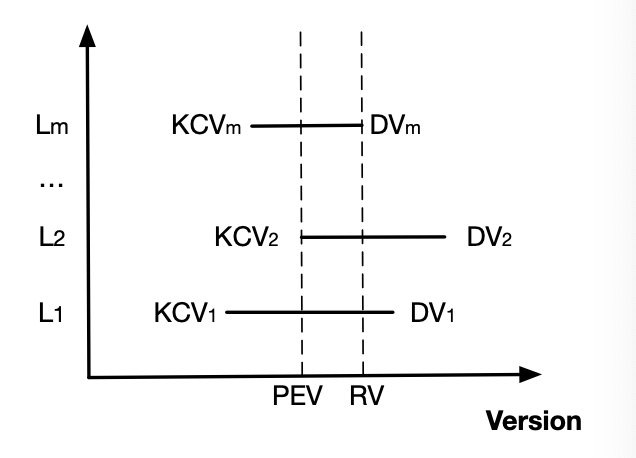
For it to be correct (that we can safely discard data after RV and preserve data before RV), the following conditions need to be met:
- DVm's cross-range-shard transaction cannot be partially committed (no rollback required).
- No clients can read any data written after DVm.
Let's try proof by contradiction on #1 and #2.
What if DMm's transaction were partially committed (specifically, rollback is required)? Notice that "partial" here specifically means cross-range-shard transaction, e.g. a transaction that sets both key A and key B, key A is stored with data in its logs, but key B is not. In this case, we have to rollback A. Logs can tolerate k-1 failures (k being the data replication factor). If at least one surviving B replica has the data for transaction DMm, no rollback is required because we have all the data for Tm, for which we will finish the commit process (heal the replication factor). Otherwise, let's say k-1 B replicas that got DMm data crashed, there must be at least one B replica up and running that has not received the DMm message. On that log, its DV must be smaller than DMm. Contradiction.
Now let's move on to #2. Notice that DV >= KCV is true locally for each log, because LSN > KCV is true on each Proxy. Log local DV can sometimes be the same as KCV because reads from the Proxies don't set DV but can bring log local KCV up to date. Even better, max(KCVs) <= min(DVs) should hold always, thanks to the fact that each log commit requires broadcasting the message to all logs. This answers our question earlier why Proxies need to broadcast each log message to all logs. Now it's obvious why #2 holds, because FDB can only serve reads based on KCV (and not DV). So for any DV > DVm, those transactions must not be committed.
With #1 and #2 combined, we can be confident that we can safely treat RV as the tail of the redo log. The presence of a KCV on a log, implies that the associated transaction is fully replicated (having k copies). It's not covered in the paper, but conceptually we can think of these messages having been durably flushed to storage nodes (safe to discard from the logs). For messages between [PEV+1, RV], they might be committed transactions. It's safe to err on the side of treating them as committed, as all writes to the logs have already passed conflict detection. These cases would be indistinguishable from reply timeouts. But due to the lack of information, we don't know for sure if messages in the [PEV+1, RV] window have been durably stored in storage nodes or not. The easiest way to handle it is to start the new epoch at PEV+1 and replay messages from [PEV+1, RV] from the old logs.
Replication Summary
Given the extreme decoupling, each component has its own replication strategy.
- Coordinator runs on Paxos, which can tolerate f failures with a cluster size of 2f+1.
- LogServers can tolerate f failures for replication factor f+1, which is orthogonal to the number of servers. Storage nodes share a similar strategy. E.g. there can be a total of 5 logs, with a replication factor of 3, which can tolerate 2 failures.
Those Claims at the Beginning
I think FDB is a great system, probably the best k/v store. However, I do think those bold claims at the beginning of the paper are, frankly, misleading.
- "FDB provides strict serializability while being lock-free". Well, to be more precise, it's meant to say the conflict detection is lock-free. Sequencer is not lock-free for example.
- "For global FDB deployment, it can avoid x-region write latency." Well, it's based on semi-sync in a local region in a different failure domain. It requires assumptions about failure domains.
- "FDB can tolerate f failures with only f+1 replicas." Well, this only applies to logs and storage nodes. If simply majority of the Coordinator fail, FDB is totally hosed for example.
Summary
FDB is probably the best k/v store for regional deployment out there. It's rock solid thanks to its simulation framework. The FDB team, in my opinion, made all the best design choices, which is just remarkable. The paper is dense. A lot of important details are only briefly mentioned or even omitted, which is probably due to the paper length limit. Congratulations to the FoundationDB team.
You are still bound by the underlying scaling bottleneck of FDB's singletons, mostly the Sequencer. ↩︎