

This is my notes on the paper: Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases.
What's Amazon Aurora
Functionally speaking, an instance of Aurora is same as an instance of MySQL. The differences are Aurora decouples compute from storage and it's fault-tolerant. It supports all ANSI isolation levels and Snapshot Isolation (or consistent read).
High Level Design
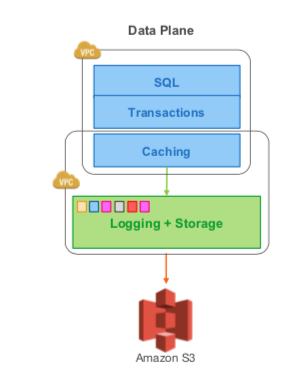
The main idea behind Aurora is that the database is the log. It disaggregates the storage, calling SQL engine and log the database, caching and storage the storage. On writes, the database replicates its log. And the application of updates from the redo log to storage is asynchronous. Storage is responsible of its own replication for durability and consistency.
Read Isolation
On reads, the database picks a read-point in the log and query the storage, which is materialized up to that read-point. Database can detect if there're any writes affecting the read results from the read-point to the time when the database sends back the read response. It can achieve Serializable Isolation by choosing to either block the write or retry the read.
Benefits
Now you can imagine you have a MySQL instance that would never run out of space. Huge efficiency wins can come from the compute storage decoupling. If your use case is space bound on MySQL today, you can imagine having ten times the storage nodes while keeping the database nodes the same.
Writes are faster because you only need to append the update to log before Aurora acknowledges the write. So, it strictly does less work up front comparing to MySQL. Besides, since the disaggregated storage itself is now replicated and distributed, the database has a better chance to avoid hitting performance outliers from disk or flash.
Replicating redo log only is pretty cheap. I agree that it should have advantage over MySQL replication. But here in the paper, it compares Aurora to a MySQL synchronous mirroring setup, which is really unfair, IMO. Why the active primary has to replicate everything over the wire to the active standby? Doesn't MySQL's replication support Statement-Based Replication?
Summary
The idea of having a replicated disaggregated WAL in front of the storage (or materialized view) is a very simple yet powerful architecture. It puts most of the complexity associated with replication, consistency and ordering in the log. Storage can then focus on durability. Cache can be updated from tailing the log, which will be kept consistent with the storage automatically. Secondary indexes (or any different views) can also be materialized by tailing the log, which provides optimized performance for certain queries.