

This is a note on Databricks' SIGMOD '22 paper - Photon: A Fast Query Engine for Lakehouse Systems, which won the best industrial paper award.
At a high level, the paper describes Photon, a vectorized query engine (written in C++) that adapts to the underlying unstructured data at run-time to achieves the state-of-the-art performance.
Architecture
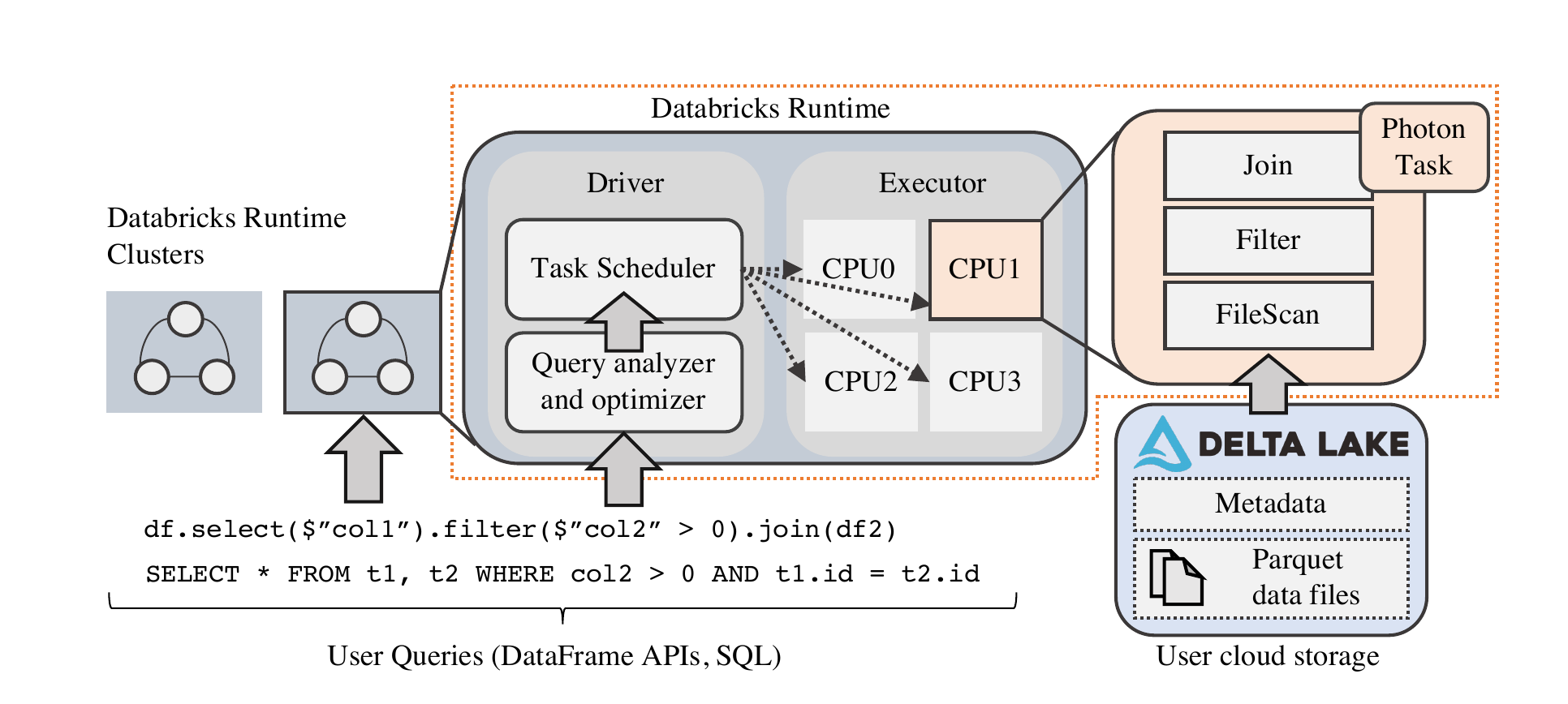
Databricks' Lakehouse architecture disaggregates compute and storage. Along with the users' cloud object storage of choice (e.g. S3, etc.), Databricks maintains metadata to support features like transactions, etc. The Databricks runtime (compute) handles all the query execution. Each query is divided into stages. Subsequent stages are blocked by the completion of earlier stages. Checkpoints are done at the stage granularity, to allow retries at stage boundaries. Each stage is further divided into tasks; each task is executed against a subset of the partitions of data. Each task uses various in-memory execution engines to process data; and Photon the execution engine is one of them. With background context out of the way, let's delve into the meat of the paper, and tradeoffs made.
Vectorized query engine
Databricks wrote Photon in C++ because the workload is becoming more CPU bound. C++ has a few advantages when it comes to optimizing the efficiency of in-memory workloads:
- more explicit control over memory pipelining and SIMD instructions
- no garbage collection.
Column batch
Photon operates against a batched columnar data layout.
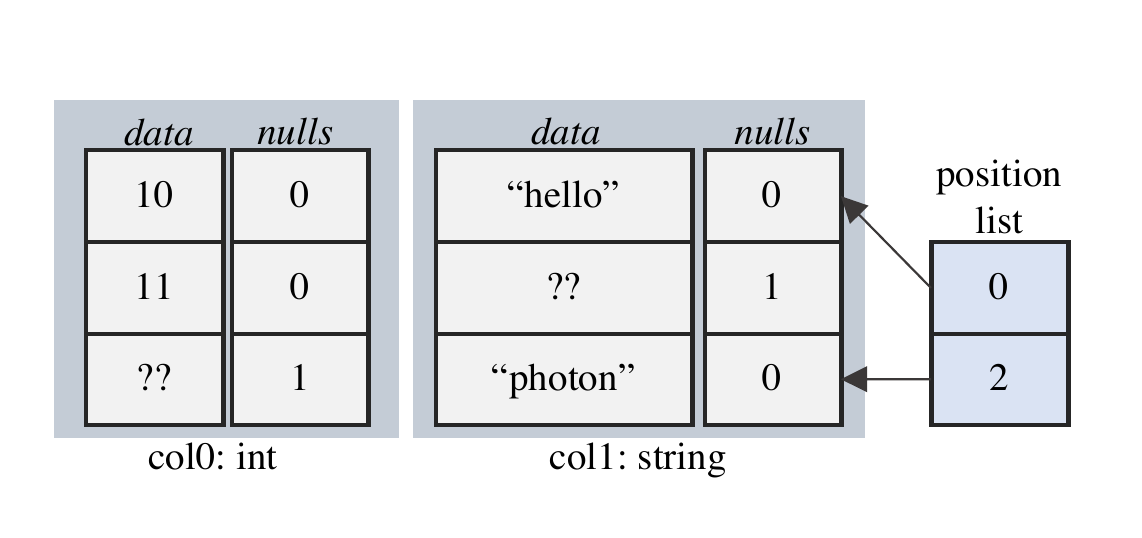
For each column vector, there is a buffer of values and a byte vector holding the NULL-ness of each value. Position list stores indices of rows in the batch that are "active". E.g. rows are filtered from the Filter operation by removing indices from the position list. You notice that this extra level of indirection is usually not a good idea; because chasing pointers leads to poor cache performance and a byte vector holding the "active-ness" seems more desirable with SIMD. However, given the workload, Databricks suggests that O(active rows) << O(batch size) most of the time, so the additional layer of indirection is still cheaper than iterating over all rows with SIMD.
Photon kernel
Having a separate NULL byte vector and position list, allows the most intensive loops in Photon to be adaptive and optimized. E.g. Here's a Photon kernel for computing square roots.

A Photon kernel is a small reusable unit of highly optimized C++ template, sometimes with hand-crafted SIMD intrinsics. The work done in Photon kernels is a function of data, independent of the shape of the query, coordination, etc. You want these kernels to be super optimized, as most of the CPU intensive work is done in these tight loops. With templates, kernels can be specialized and certain code be elided for high performance. In the example above, the entire branch condition is compiled away at compile time and zero cost is paid at runtime, based on kHasNulls and kAllRowsActive. If all rows are active, the code will skip the position list and use row_idx directly.
At the beginning, we mentioned that data in the lakehouse can be unstructured. To deal with this uncertainty, Photon, at runtime, builds metadata about a column batch and uses it to optimize its choice of kernels. Each kernel can adapt to at least two variables: NULL-ness and activeness (as we have seen in the previous example). Other specializations include, ASCII vs. unicode, UUID, etc.
The design is fairly flexible as each Photon kernel can make localized decisions, which adapts well given the uncertainty of the workload. Section 6 has all the benchmark results, and demonstrates the benefit of runtime adaptivity, and memory pipelining (with SIMD). Databricks holds the current TPC-DS world record.