

This is a note on Louis Brandy and Nathan Bronson's talk at Systems @scale - https://www.facebook.com/atscaleevents/videos/5279535778820968/.
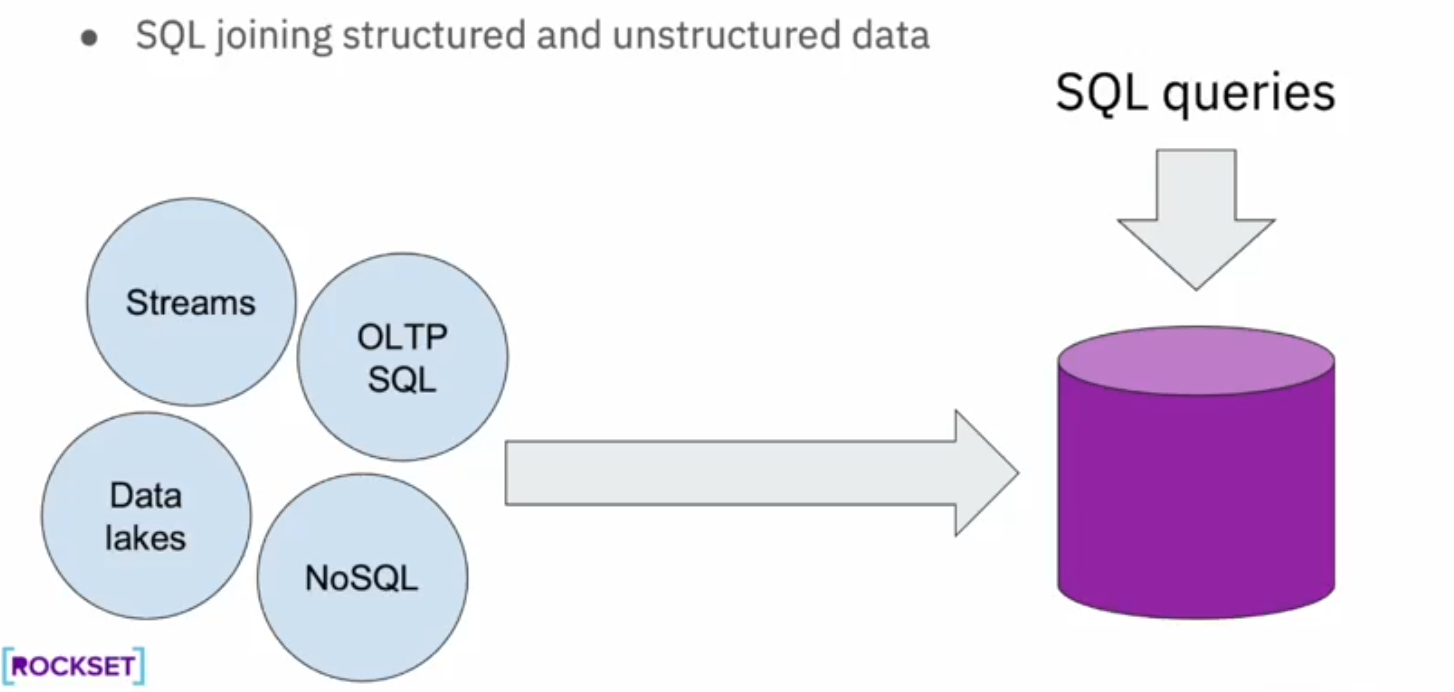
Data generated from the customers are often schemaless (e.g. JSON), but fast SQL for analytical queries are desired out of this unstructured data. Having fast query performance and less rigidity of the data schema are usually contradictory goals. Let's see how Rockset solves this problem.
Vectorized query engine
The overall strategy taken by Rockset is very similar to Databricks' Photon, as both use vectorized query engines. The query engine operates against a batch (array) of inputs of a specific type, so C++ templates can be specialized for fast execution in those tight loops inside the query engine. Rockset infers the type by examining the query text and column names.
Vectorization is a good fit for dynamic schemaless workloads because you can batch type checks (e.g. here's an array of integers) before dispatching the work to the query engine, compared to doing type checks per row.
Index nested structure
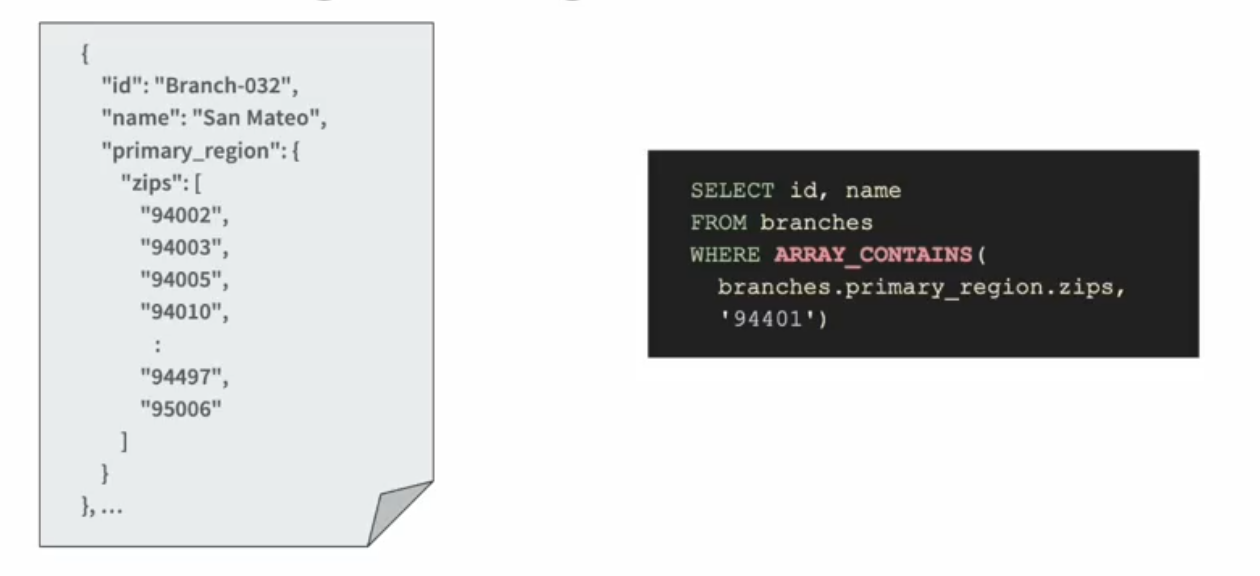
JSON objects can be nested and schemaless. One classic solution is to perform ETL to flatten the data, and run SQL on top. But that's complicated and makes the data schema rigid. We want to ingest the data as it comes (as raw JSON), and still build indices on the data and support fast queries.
We often think of inverted indices as a map from values to documents (value -> documents); but actually inverted index is a map from (column, value) to documents. It's just that most of the time the column name is implicit. From this insight, Rockset uses field paths as column names; and they get an inverted index that looks like,

So if we are looking for docs with name="San Mateo", we can construct the lookup key and do a point lookup. This is pretty cool but it doesn't work very well for the ARRAY_CONTAINS operator in our example.
SELECT id, name
FROM branches
WHERE ARRAY_CONTAINS(branches.primary_region.zips, '94401')
Usually we don't know the index of an array when we are querying the data. Here Nathan brought up a good and deep insight,
Take everything we don't expect to know and move from the left side of the index to the right.
The "thing we don't expect to know" in this case, is the array index. The result inverted index looks like this,

Now we only require a single point query to support the previous example query.