

If you are operating some stateful services, chances are you have to replicate your data. There are use cases of single replica database, in which cases, the user can tolerate dataloss. It's optimizing for throughput, low latency, etc. But vast majority of stateful services have to deal with replication. Replication here literally means storing multiple copies of your data, to satisfy the durability requirement.
There are many ways you can choose to do replication. In this post, we are going to discuss, in my opinion, two most popular options, Paxos/raft-based replication, and Leader-Follower replication. For each one, we will look at what consistency guarantee it can provide, latency on read/write, throughput, and availability, etc.
Setup
In order to concretely inspect each replication method, let's establish a common setup. Let's say we are building a database that needs to have three replicas distributed in three different regions around the globe. Distributing them geographically, so that it can tolerate nature disasters better.
Query pattern and client consistency/availability requirements are intentionally left out so that we can discuss those separately for each replication method.
Paxos Replication
I also have another post explaining single decree Paxos.
Before talking about Paxos in detail, let's have a quick look at synchronous replication. The most straightforward synchronous replication setup is to write to all three copies, before acknowledging the client write query.
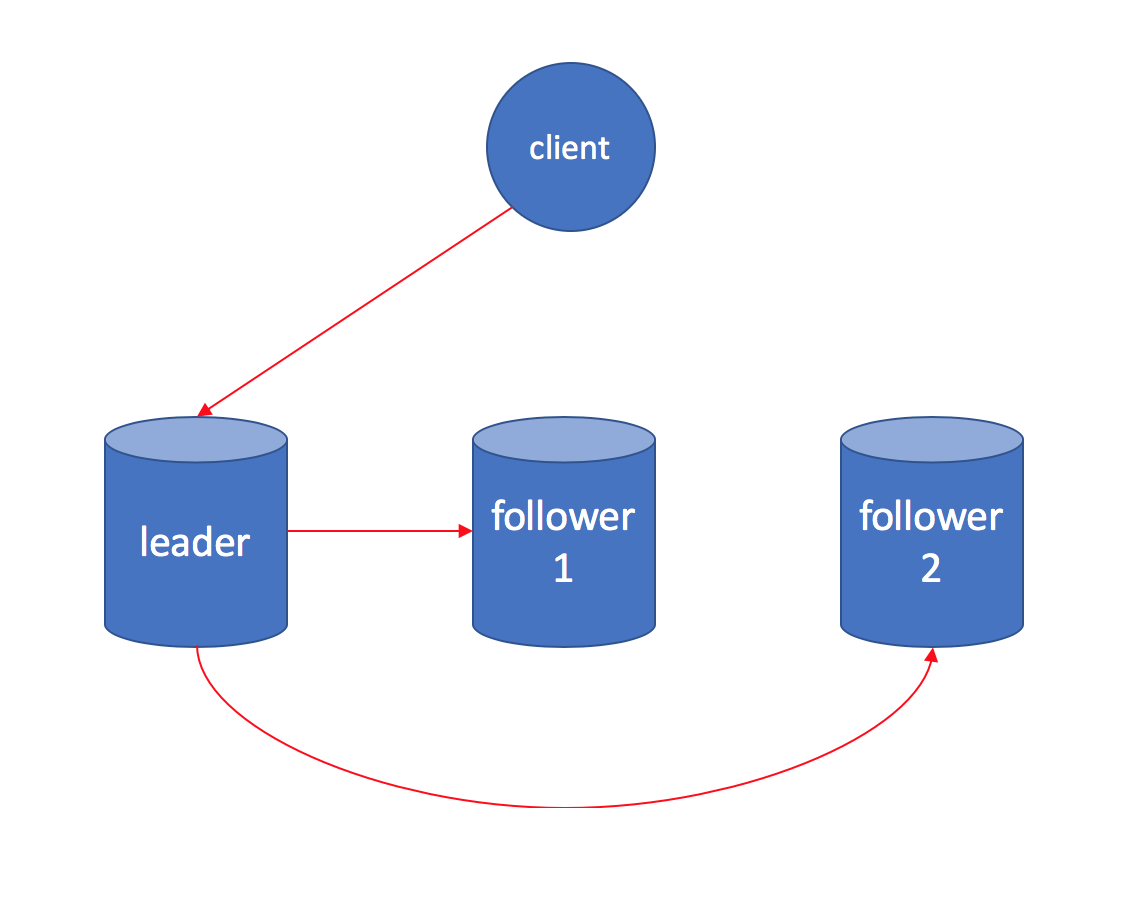
All writes are serialized on the single leader and synchronously replicated to the other two followers. And it provides CAP Consistency (a.k.a linearizability). I will define fault tolerant to be that clients will not notice failures of minority nodes, and the system will operate as if all nodes are running healthy. Apparently synchronous replication is not fault tolerant, not even close to CAP Available.
Paxos replication differs from the simple synchronous replication in two ways. First, it only requires talking to the majority of the nodes instead of all of them. Second, it's a two phase protocol, instead of a single phase protocol. Also when we say "Paxos Replication", it usually means Multi-Paxos, for replicating a log of actions. Multi-Paxos itself is loosely defined, since there are many different ways of doing it. The gist is to run single Paxos for each slot of the log entry.
Consistency
Paxos replication is a form of synchronous replication with fault tolerance. It's fault tolerant, but it doesn't mean it's CAP Available. And in fact, it's not CAP Available. It provides CAP Consistency, which is the strongest consistency guarantee we can have, that all operations are linearized. Borrowing Daniel Abadi's example, it's the only way to guarantee Y == 18 in the following example:
X = 10;
Y = X + 8;
I just lied, sort-of. CAP Consistency is not necessarily required to make Y == 18. Read-what-you-wrote is enough if reading X is on the same process of writing X. We will discuss read-what-you-wrote very soon. But read-what-you-wrote has its obvious limitation, specifically on the "you" part. CAP consistency is effectively read-what-everyone-wrote. So in the example above, if the process writing X is not the same that's reading X, and there's a happened-before ordering between the two, read-what-you-wrote is not sufficient.
CAP Consistency is the best you can ask for. A distributed database will work as if there's only one replica. It doesn't get better than this. (Spanner offers external consistency, which is similar.)
Latency
We don't get CAP Consistency for free. In order to linearize all operations, each one of them needs to talk to at least two out of three replicas we have. Since it's geographically distributed, and light can only travel this fast, the latency impact is not negligible. Usually, each operation can take hundreds of milliseconds to finish, the outliers (99 percentile) would be worse. It's possible to do reads outside of Paxos, when client doesn't require strong consistent read at per query granularity. This would help improve read latency and throughput.
Throughput
Latency impact doesn't necessarily translate to throughput impact since we can do batching. According to Daniel Abadi's post, a single Paxos group can scale up to half a million transactions per second with batching!
Availability
Like I said earlier, Paxos based replication is fault tolerant. As long as majority of the nodes are up and running, things are still working fine. But it's not CAP Available. Once the number of running nodes fell below F+1 in a cluster of total 2F+1 nodes, Paxos based replication can no longer accept new operations. Even though it's not CAP Available, from client's perspective, the service will rarely experience any downtime.
Client Preference
Paxos replication is great for multi-tenant database, thanks to its strong consistency guarantee. It works equally well for write heavy or read heavy workload. Clients, that are not very latency sensitive, would find Paxos based replication a pretty good fit.
Leader-Follower Replication
Example: MySQL, PostgresSQL
This is probably the single most popular setup in the industry as far as I can tell, thanks to the wide adoption of MySQL and other very well-built relational databases.
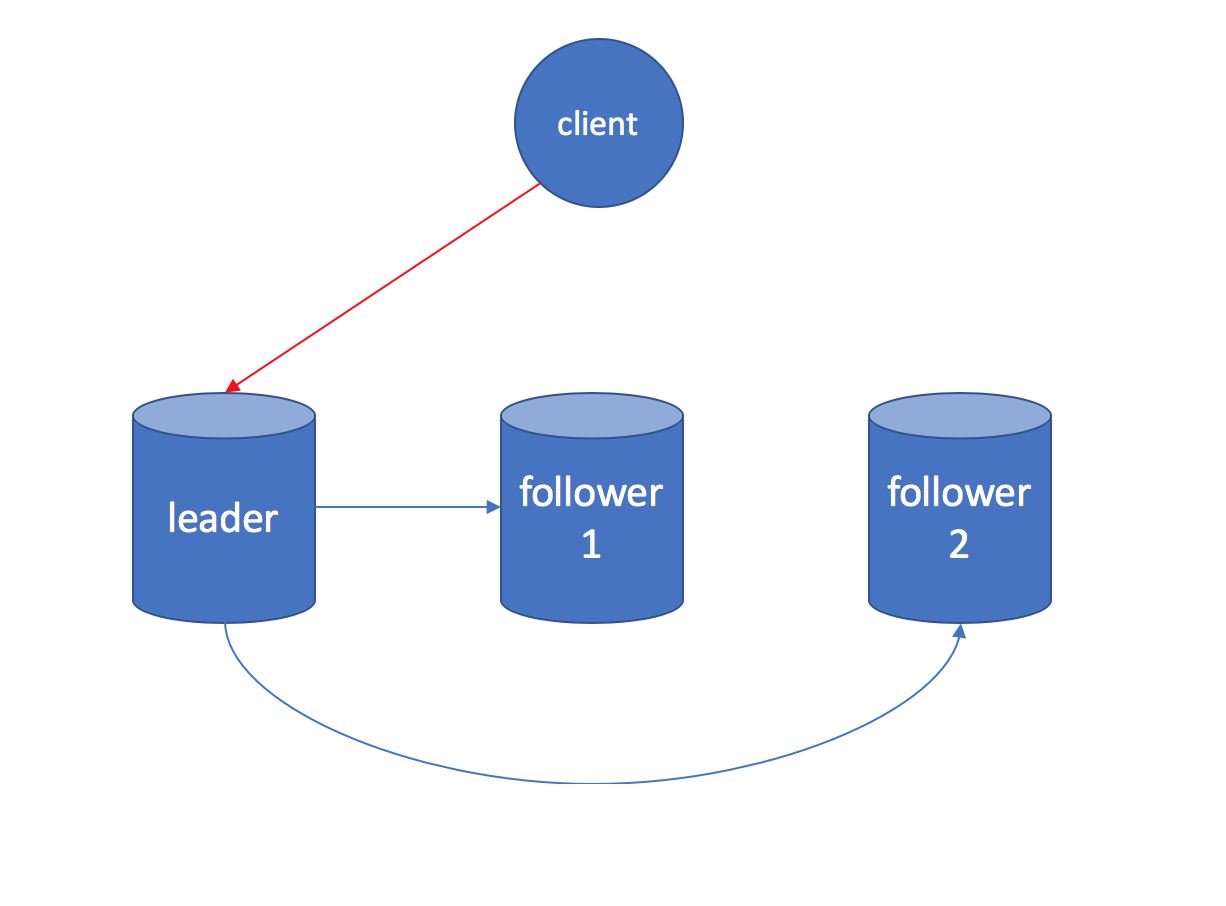
In this case, the red line is client write query, and blue lines are asynchronous replication from leader to followers.
Consistency
By default, Leader-Follower replication provides Eventual Consistency. It's the weakest among CAP Consistency, read-what-you-wrote consistency, and causal consistency. (CAP Consistency > Causal Consistency > Read-what-you-wrote Consistency > Eventual Consistency.) It's not causal consistent. E.g. Alice reads the DB and found the final score of the World Cup Final. And she sends a message to Bob. Bob then reads from the DB, hitting a follower, which shows the match is still on-going. It's not read-what-you-wrote consistent either, because you can read from a follower that doesn't have the latest data replicated. (Causal consistency implies read-what-you-wrote consistency.)
We can however, make it support read-what-you-wrote consistency by using features like MySQL GTID. For each write, client gets back a GTID representing the write, uniquely. When doing the read, the client can pass in the GTID from the initial write, and the follower can detect if it's lagging w.r.t the GTID, to decide if it's fresh enough to serve the read query. If data is not sharded, it can also support CAP Consistency by doing reads always on the leader.
Latency && Throughput
Its read/write latency is better than Paxos based replication, since client only needs to talk to one replica/region. Client only needs to talk to more than one region when the local follower is lagging and client requires read-what-you-wrote consistency.
Client can also batch requests to the underlying database to improve throughput. Since Paxos is a two phase protocol, Leader-Follower setup will definitely have a much higher throughput, which means fewer machines to serve the same qps(query per second).
Availability
If leader is down, no writes can be processed any more, so it's not fault tolerant. So downtime is inevitable with Leader-Follower replication setup. The focus should be how to reduce the impact of downtime. Usually tooling needs to be built to promote a follower into a leader. Notice that this is more complicated than just flipping a bit in settings. In order to avoid dataloss, leader is required to synchronously replicate its data to a second copy. This is to ensure that when the leader is dead, we don't lose data that's acknowledged to the client but not replicated to any followers. Another way to reducing impact is to shard the data into many shards. In this way, when a leader is down, only shards mastered on the leader are impacted.
Client Preference
Leader-Follower setup is good for read heavy workload, as followers can handle the read traffic but only leader can handle writes. It's a good fit for latency sensitive clients that only require read-what-you-wrote consistency and can tolerate brief downtime on some of the shards.
Other Replication Scheme
There are other ways of doing replication that do not fit into either the Paxos model or Leader-Follower model. The most popular one might be DynamoDB and its decedents (e.g. Cassandra). It's close to Leader-Follower in a sense that the coordinator node will replicate the data to all nodes in the Preference List asynchronously. But either the leadership or the preference list is deterministic. They can change during fail-over or cluster expansion. It provides same default consistency guarantee as Leader-Follower setup. It's CAP Available, the highest availability level we can get by design. Clients that are write heavy, and require super high availability would find Cassandra and Dynamo very appealing.