The basic concept of a read-write lock is simple. It allows multiple readers to access the resource simultaneously, but at most one thread can have exclusive ownership of the lock (a.k.a write lock). It's supposed to be an optimization, comparing to simple mutex (e.g. std::mutex). As in theory, multiple readers do not contend. Naively, read performance should scale linearly. However, this is not the case in practice for most read-write locks, due to cacheline pingpong-ing.
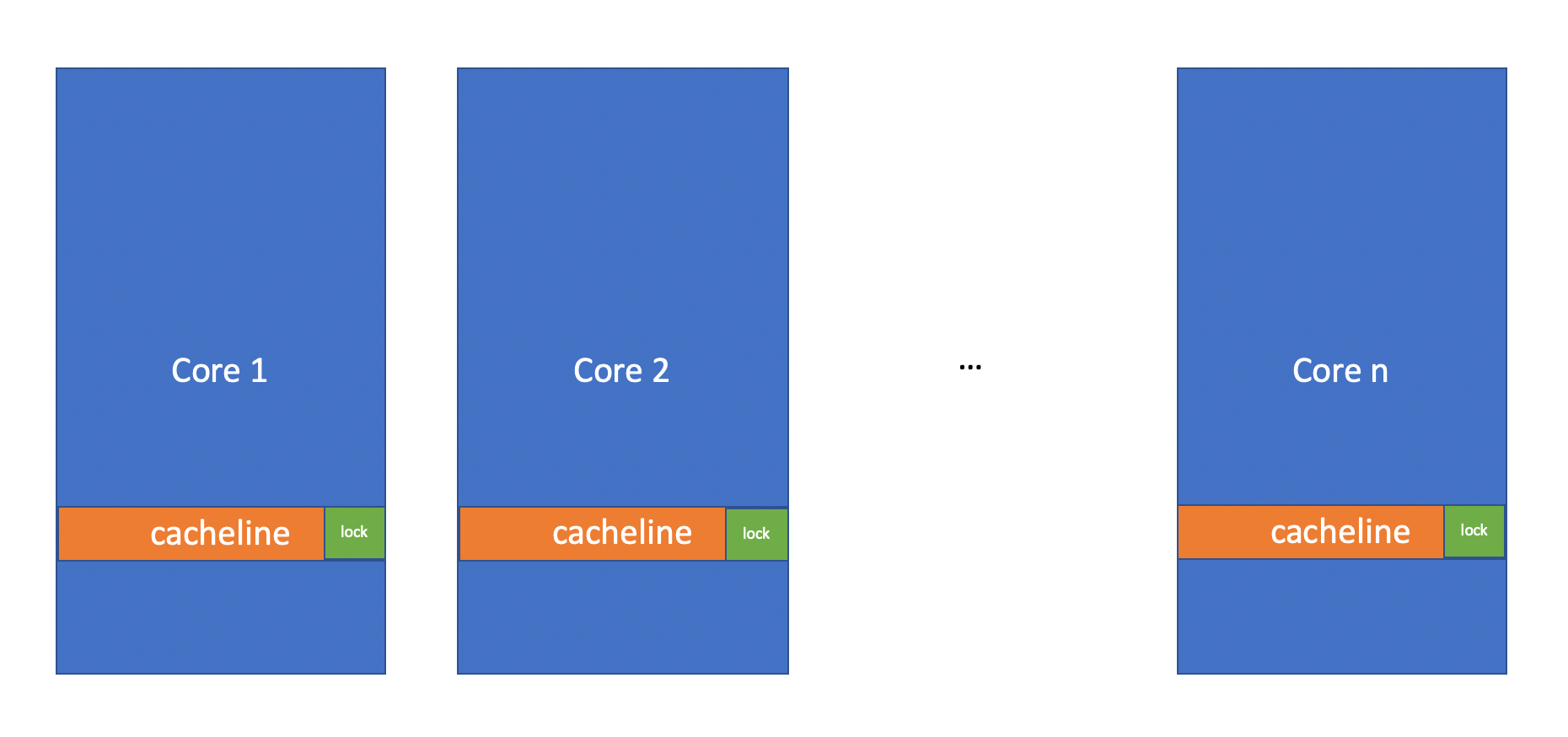
Let's say N threads are running on N cores, all trying to get shared ownership of the mutex (read lock). Because we need to keep a count of the number of active readers (to exclude writers), each lock_shared() call needs to mutate the mutex state.

And CPU needs to keep cache coherent. It needs to invalidate cachelines in other cores of the same address.
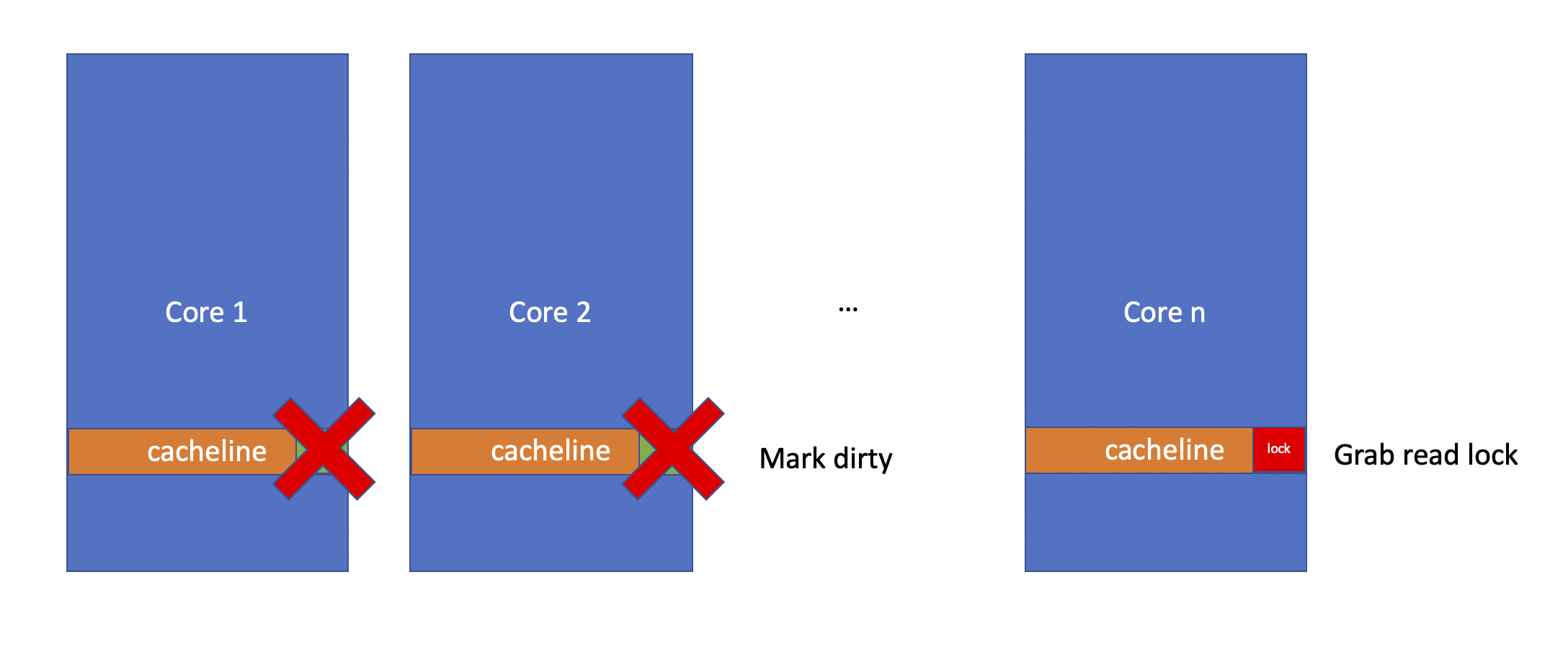
Now if Core 1 wants to get the lock in shared mode, it will get a cache miss. An L1 cache hit takes about 4 CPU cycles. Main memory access usually takes 20x more CPU cycles if not more. In Jeff Dean's famous latency table, L1 cache hit takes about 0.5 ns, and main memory access is about 100 ns. In this way, the performance doesn't scale linearly as you throw more readers to the data. By increasing the number of threads, you often end up with 10x power assumption and maybe 20% performance improvment over single reader.
How folly::SharedMutex solves the problem
folly is Facebook's C++ open source library. folly::SharedMutex solves this problem by storing active readers in a global static storage. It stripes the shared storage, so each reader takes a whole cacheline. It tries to have a sticky routing from a given core to the slot in the shared memory for reducing search overhead. Each slot stores the address of the mutex. In this way, when another reader comes in, it only needs to mutate the shared storage, and leaves the mutex state unchanged.
Voilà! No more cacheline pingpong-ing!
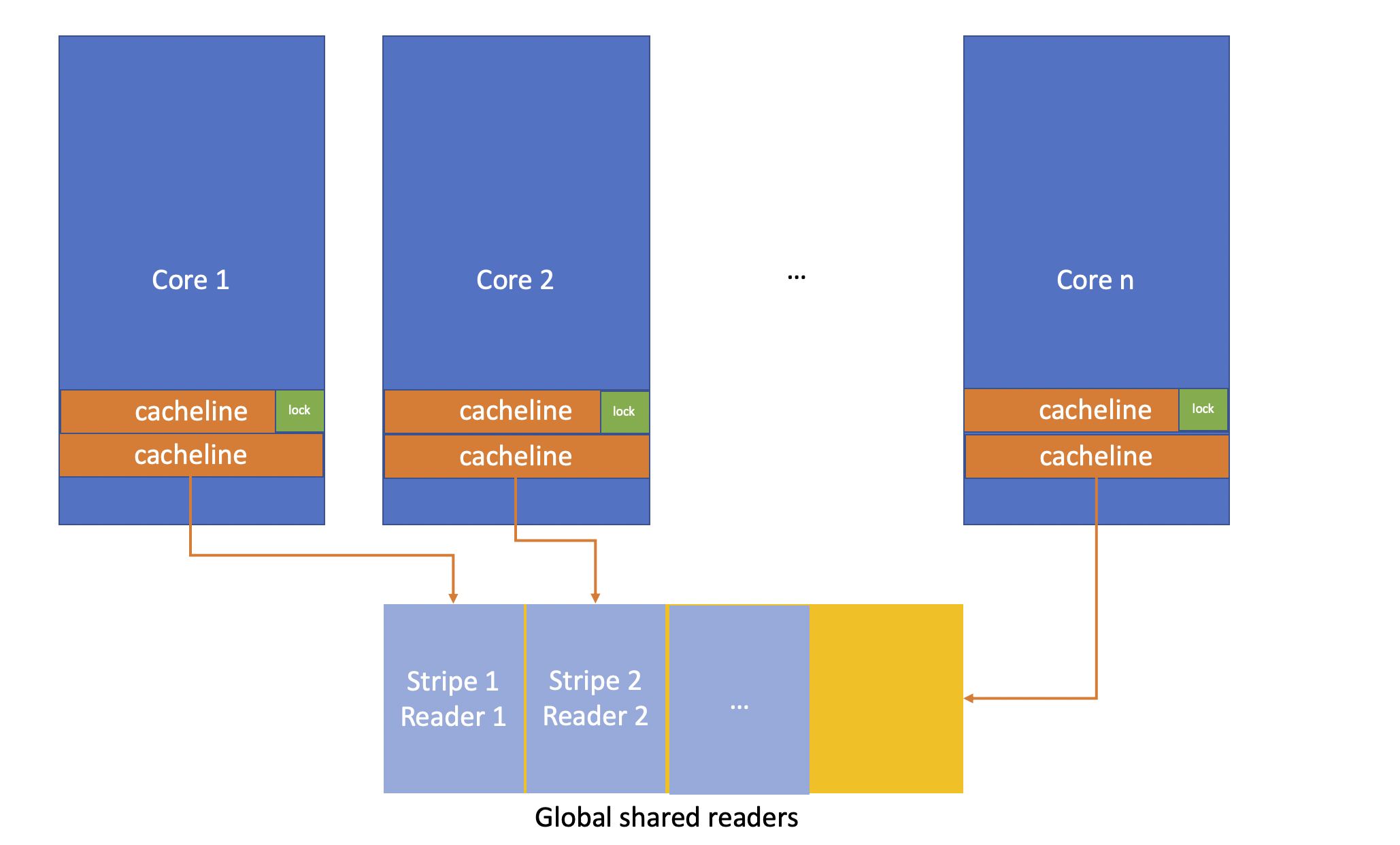
However, it does come with a downside. Because all deferred readers share the same block of static memory, this means
acquisition of any lock in write mode can conflict with acquisition of any lock in shared mode
(https://github.com/facebook/folly/blob/master/folly/SharedMutex.h)
E.g. A writer, of a given mutex, might have most of the deferred reader array pre-fetched in memory, but readers of other mutex might cause the cacheline to be invalidated. And most of the time the write and the read are not even contending on the same lock object. But the cacheline gets invalidated anyway.
The benefit of SharedMutex is most significant when there are many concurrent readers, and there are actual contention. For cases where actual concurrent reads is rare, spin lock works better. That's why folly::SharedMutex actually degenerates to an inlined read-write lock (which stores the reader count inline) when there are no concurrent readers detected. This is done dynamically at runtime.
Details
The devil is in the details.
How to block
How do we block when we need to, E.g. reader waiting for an active writer, or writer waiting for multiple outstanding readers? You don't want to call FUTEX_WAIT every time you block, as system calls are expensive. folly::SharedMutex blocks in following order
- spin with
pauseinstruction std::this_thread::yield()- FUTEX_WAIT
If there's no contention or the contention is short lived, spinning wait is the fastest, with no system calls. PAUSE instruction is used to avoid expensive pipeline flush when exiting the loop. (https://c9x.me/x86/html/file_module_x86_id_232.html)
If it exhausts the spinning wait tries, it moves on to sched_yield(). It will give the other thread opportunities to release the lock and avoid burning through too many CPU cycles busy waiting.
At the very end, it calls FUTEX_WAIT if both spin-wait and yield are exhausted. All the states related to a given mutex is encoded in the 32bit futex and the external deferred reader array.
How lock/unlock works
All the synchronizations required are done based on a single 32bit atomic futex. A common pattern of how lock works looks like:
- block until
stateshows no contention withacquiresemantic - if the lock is inlined, perform CAS on the atomic state. Only return, when CAS succeeds (except this is try_lock, or timeout is allowed).
- if the lock is not inlined
- if not already set, perform CAS on the atomic state to block other exclusive operations (e.g. set the "has_deferred_reader" bit in the state for
lock_shared(), if not already set) - create deferred reader slot in global static memory
- read state again with
acquiresemantic - if the "has_deferred_reader" bit is still set, return success
- retry the whole operation
- if not already set, perform CAS on the atomic state to block other exclusive operations (e.g. set the "has_deferred_reader" bit in the state for
Setting the "has_deferred_reader" bit will block the acquisition of the lock in exclusive mode. However it's possible that after a deferred reader slot is written, the previous last deferred reader exists the lock and clears the "has_deferred_reader" bit. Or even worse, some writer might have even started acquiring the lock in exclusive mode. That's why we need to read the atomic state again to check the "has_deferred_reader" before we can return from lock_shared(). If we have the deferred reader registered, and "has_deferred_reader" is set in the state, it's impossible for another writer to successfully get exclusive ownership of the lock. So we can safely return.
For lock() (lock exclusive), it sometimes needs to wait for all the deferred readers to exit the lock. But for deferred readers, we are not keeping a refcount inline anymore. So folly::SharedMutex in this case, would move all the deferred readers back inline, and then FUTEX_WAIT on the state until the refcount reaches zero.
Unlock just calls FUTEX_WAKE. But again, the devil is in the details. Whom do we wake up? How many threads do we wake up?
Whom to wake up
If there are multiple writers waiting for the mutex, when the last reader exits, it's most efficient to just wake up one writer instead of all of them. This is done using a special bit from the atomic state. Only the first writer waiter will set this bit, and only this thread will be waken up.
On the other hand, if there are multiple readers waiting for the active writer to exit the lock, all the them will be waken up at once.
What if we run out of slots
If no slots are available, readers are inlined. They are refcounted inside the 32bit atomic futex.
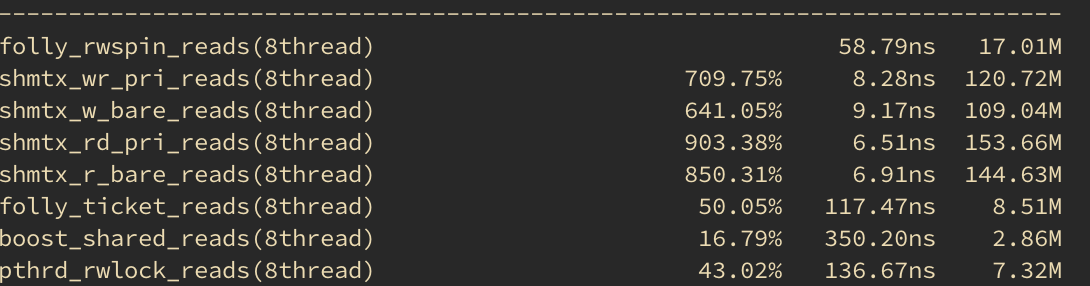
Benchmark
You can run the benchmark on your own hardware. On my machine (32KB L1 cache per core, dual-socket, 24 cores with hyperthreading enabled), folly::SharedMutex is better than other mutexes in most of the cases, and in some cases significantly faster. When it's slower than other mutexes, it's usually only few ns slower.