

std::atomic combines read-modify-write atomic instructions, memory barriers in hardware and memory order concept in C++ altogether. It's commonly used for lock-free programming, which often looks like,
if (futex.compare_exchange_strong(expected, 1, memory_order_acquire)) {
// lock acquired
}
Multiple Caches
Data race doesn't exist until we had computers with multiple cores and programs with multiple threads.
When there's only a single core, there's a single copy of data from its perspective – its L1 cache. With multiple cores, each having their own L1 cache and L2 cache, keeping data in multiple caches in sync is a distributed system problem. Just like it's always easier to reason about if there's a single instance of MySQL that has all of your data and you don't have to worry about sharding and replication (and this is why Spanner is popular).
Keeping multiple CPU caches in sync is what known as cache coherence.
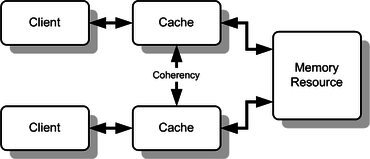
Cache is coherent if it meets the following requirements,
Write Propagation
Changes to the data in any cache must be propagated to other copies (of that cache line) in the peer caches.
Writes from a different core must be visible the other cores.
Transaction Serialization
Reads/Writes to a single memory location must be seen by all processors in the same order.
If core P writes A to memory location L then B, no one can read B before A.
Notice that Cache Coherence is a property applied to a single memory location. It doesn't specify anything if core P1 writes to memory location L1 and P2 writes to memory location L2.
If accesses to all memory locations are serializable, it's called Sequential Consistency. In distributed system term, it's the same as Serializability.
MESI
MESI is a common cache coherence protocol. It supports write-back cache, hence having very good performance. A cacheline in MESI can be only in one of four possible states:
- modified
- This is when the data is modified and not written back to main memory yet. Reads from main memory of the data is not allowed. The data can't be present in cachelines of other CPUs.
- exclusive
- The cacheline is only present in the current cache. The data matches main memory.
- shared
- There can be multiple copies of the cacheline in other caches. The data matches main memory.
- invalid
- The cacheline is invalid and can't be used.
It might seem complicated, especially if you try to follow all the possible state transitions. But it's really not. Thanks to Bus snooping, any cache state change is atomically broadcast to all other caches. It essentially implements Atomic Broadcast, which is not a trivial problem in distributed system due to possible partial failures. However we don't have to worry about partial failures when it comes to multiple caches in a single machines.
Store Buffer and Invalidation Queue
If you read through the MESI model, it does provide Sequential Consistency (not surprising if it's doing atomic broadcast all the time). However the existence of Store Buffer and Invalidation Queue destroys it.
Store Buffer
When P is trying to write to its cache and its cache state is "invalid", it needs to first fetch the cacheline from main memory (or transfer from other caches) before it can set exclusive ownership of the cacheline and set its state to "modified". This can be very slow, hence the introduction of Store Buffer.
In this case, writes get buffered in the cache-local store buffer after issuing read-invalidates to all caches. The cacheline will be eventually updated with the written value after it's fetched from main memory. During this window, read from the cache will have to search for its store buffer for buffered writes. It works for the local cache but not others.
Note that while a CPU can read its own previous writes in its store buffer, other CPUs cannot see those writes before they are flushed from the store buffer to the cache - a CPU cannot scan the store buffer of other CPUs. (https://en.wikipedia.org/wiki/MESI_protocol#Memory_Barriers)
Linus explains it very well in one of his emails:
HOWEVER. If you do the sub-word write using a regular store, you are now
invoking the one non-coherent part of the x86 memory pipeline: the store
buffer. Normal stores can (and will) be forwarded to subsequent loads from
the store buffer, and they are not strongly ordered wrt cache coherency
while they are buffered.
IOW, on x86, loads are ordered wrt loads, and stores are ordered wrt other
stores, but loads are not ordered wrt other stores in the absence of a
serializing instruction, and it's exactly because of the write buffer.
Invalidation Queue
When a core receives invalidation message from another, it acknowledges it and applies the invalidation asynchronously. Unlike store buffer, local core cannot scan invalidation queue for reads.
This is why we need memory barriers. A store memory barrier flushes the store buffer to main memory, so it becomes globally visible. This can also be implemented as blocking loads globally until writes are flushed to main memory, which has the same effect.
A load barrier will flush the invalidation queue, hence writes from other CPUs become visible to the local cache. Now you understand why passing data from one core to the other requires a store with store barrier and a load with load barrier.
We shouldn't need to worry about context switch as it seems perfectly reasonable to drain the store buffer and invalidate the CPU cache on context switch.
Reordering
As if Store Buffer and Invalidation Queue is not complicated enough, there are compiler reordering and CPU reordering. Jeff Preshing has many good posts about memory model and this one talks about catching CPU reordering in action.
There's a structure called Load Queue in CPU that performs loads speculatively (out of order).
Memory Barrier
You often see asm volatile("" ::: "memory"); when you want to prevent compiler to recorder reads and writes.
In order to deal with CPU reordering and the lack of sequential consistency (thanks to store buffer and invalidation queue) CPU fences are often used. On x86, we have three fences mfence, sfence and lfence. CPU fences are implicit compiler fences.
Jeff Preshing has a good post about memory barrier. Generally there are four types of fences #LoadLoad, #LoadStore, #StoreLoad and #StoreStore.
#LoadLoad is useful when you want to prevent reordering between reads. This is especially useful when a thread is consuming some data depending on a flag e.g. isPublished written by another thread, so reading the data always happens after checking the flag.
Similarly #StoreStore fence is used to prevent reordering writes (sfense on x86). This is useful when a thread is publishing some data using a flag, so writing the data always happens before setting the flag.
#LoadStore fence disallows reordering a subsequent store ahead of the load instruction, which typically happens on CPU when the later store is a cache hit and the earlier load is a cache miss.
#StoreLoad is unique and it acts as a full sync (full memory barrier, mfence on x86) – all writes before the fence will be made visible to all other caches and all reads after the fence will get values at-or-later than the execution time of the fence. If all operations have #StoreLoad fences, it would be sequential consistent.
x86 implementation
mfence (https://www.felixcloutier.com/x86/mfence)
Performs a serializing operation on all load-from-memory and store-to-memory instructions that were issued prior the MFENCE instruction. This serializing operation guarantees that every load and store instruction that precedes the MFENCE instruction in program order becomes globally visible before any load or store instruction that follows the MFENCE instruction. The MFENCE instruction is ordered with respect to all load and store instructions, other MFENCE instructions, any LFENCE and SFENCE instructions...
In practice, it drains the store buffer before any loads (globally) can proceed.
sfence (https://www.felixcloutier.com/x86/sfence)
Orders processor execution relative to all memory stores prior to the SFENCE instruction. The processor ensures that every store prior to SFENCE is globally visible before any store after SFENCE becomes globally visible. The SFENCE instruction is ordered with respect to memory stores, other SFENCE instructions, MFENCE instructions, and any serializing instructions (such as the CPUID instruction). It is not ordered with respect to memory loads or the LFENCE instruction.
It doesn't have to drain the store buffer. It's often used for Non-temporal instructions, when by default, operations bypass cache and "breaks" cache coherence explicitly. Inserting sfence after an NT store, makes sure the data becomes visible to other cores.
lfence (https://www.felixcloutier.com/x86/lfence)
Performs a serializing operation on all load-from-memory instructions that were issued prior the LFENCE instruction. Specifically, LFENCE does not execute until all prior instructions have completed locally, and no later instruction begins execution until LFENCE completes. In particular, an instruction that loads from memory and that precedes an LFENCE receives data from memory prior to completion of the LFENCE.
In practice, it drains the local invalidation queue and re-order buffer (load queue). I am not aware of when this is useful on x86.
x86 is considered having a strong memory model. The best definition I can find is
A strong hardware memory model is one in which every machine instruction comes implicitly with acquire and release semantics. As a result, when one CPU core performs a sequence of writes, every other CPU core sees those values change in the same order that they were written.
On x86, barring non-temporal instructions, all reads have acquire semantic and all writes have release semantic. This means you get lfence and sfence for free. But lfense + sfence != mfence or full memory barrier. Specifically, for #StoreLoad, you can reorder an acquire-load ahead of a release-store. In fact, it does happen on x86.
Read-modify-write operation
Read-modify-write operation is related to memory barrier as well. e.g.
a.fetch_add(1, std::memory_order_relaxed); // std::atomic<int> a(0);
gets compiled to the following assembly on GCC
lock xadd DWORD PTR [rax], edx
lock is a signal prefix, which ensures that read-modify-write (xadd in this case) is executed atomically. It also acts as a full memory barrier just like xchg on x86. On other platforms, it's possible that a successful RMW has different memory order, which is allowed in C++ standard atomic APIs as well.
Acquire and Release
Now let's switch to C++ and talk about high level memory order. Acquire-read disallows reordering reads or writes ahead of it, in program order. Release-write disallows reordering reads or writes after it, in program order. It says nothing about fences, which is just implementation detail. In practice it looks like (https://preshing.com/20120913/acquire-and-release-semantics/):

On x86 this is the default behavior without extra memory barriers needed. With weak memory model, reorder can happen.
Now back to the example in the beginning of the post,
if (futex.compare_exchange_strong(expected, 1, memory_order_acquire)) {
// lock acquired
}
- It issues atomic instruction e.g.
lock cmpxchgon x86 to perform read-modify-write on thestd::atomicfutex. - If the RMW operation succeeds, requires
acquiresemantic for the RMW operation. This is needed so no instructions inside the critical section get reordered above the RMW operation. Same thing applies to releasing the lock, where you perform a release-store, to prevent reordering instructions after the release operation.
Here's a real world example. In Folly MicroSpinLock(https://github.com/facebook/folly/blob/master/folly/synchronization/MicroSpinLock.h), the lock acquisition code is
bool cas(uint8_t compare, uint8_t newVal) noexcept {
return std::atomic_compare_exchange_strong_explicit(
payload(),
&compare,
newVal,
std::memory_order_acquire,
std::memory_order_relaxed);
}